15. Missing Data and Other Opportunities
Contents
![]()
15. Missing Data and Other Opportunities¶
# Install packages that are not installed in colab
try:
import google.colab
%pip install -q watermark
%pip install git+https://github.com/ksachdeva/rethinking-tensorflow-probability.git
except:
pass
%load_ext watermark
# Core
import collections
import numpy as np
import arviz as az
import pandas as pd
import xarray as xr
import tensorflow as tf
import tensorflow_probability as tfp
# visualization
import matplotlib.pyplot as plt
from rethinking.data import RethinkingDataset
from rethinking.data import dataframe_to_tensors
from rethinking.mcmc import sample_posterior
# aliases
tfd = tfp.distributions
tfb = tfp.bijectors
Root = tfd.JointDistributionCoroutine.Root
2022-01-19 19:15:07.800238: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory
2022-01-19 19:15:07.800287: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
%watermark -p numpy,tensorflow,tensorflow_probability,arviz,scipy,pandas,rethinking
numpy : 1.21.5
tensorflow : 2.7.0
tensorflow_probability: 0.15.0
arviz : 0.11.4
scipy : 1.7.3
pandas : 1.3.5
rethinking : 0.1.0
# config of various plotting libraries
%config InlineBackend.figure_format = 'retina'
Code 15.1¶
# simulate a pancake and return randomly ordered sides
def sim_pancake():
pancake = tfd.Categorical(logits=np.ones(3)).sample().numpy()
sides = np.array([1, 1, 1, 0, 0, 0]).reshape(3, 2).T[:, pancake]
np.random.shuffle(sides)
return sides
# sim 10,000 pancakes
pancakes = []
for i in range(10_000):
pancakes.append(sim_pancake())
pancakes = np.array(pancakes).T
up = pancakes[0]
down = pancakes[1]
# compute proportion 1/1 (BB) out of all 1/1 and 1/0
num_11_10 = np.sum(up == 1)
num_11 = np.sum((up == 1) & (down == 1))
num_11 / num_11_10
2022-01-19 19:15:10.311510: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcuda.so.1'; dlerror: libcuda.so.1: cannot open shared object file: No such file or directory
2022-01-19 19:15:10.311557: W tensorflow/stream_executor/cuda/cuda_driver.cc:269] failed call to cuInit: UNKNOWN ERROR (303)
2022-01-19 19:15:10.311581: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:156] kernel driver does not appear to be running on this host (fv-az272-145): /proc/driver/nvidia/version does not exist
2022-01-19 19:15:10.311925: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
0.6658072193573978
15.1 Measurement error¶
Code 15.2¶
In the waffle dataset, both divorce rate and marriage rate variables are measured with substantial error and that error is reported in the form of standard errors.
Also error varies across the states.
Below we are plotting the measurement errors
d = RethinkingDataset.WaffleDivorce.get_dataset()
# points
ax = az.plot_pair(
d[["MedianAgeMarriage", "Divorce"]].to_dict(orient="list"),
scatter_kwargs=dict(ms=15, mfc="none"),
)
ax.set(ylim=(4, 15), xlabel="Median age marriage", ylabel="Divorce rate")
# standard errors
for i in range(d.shape[0]):
ci = d.Divorce[i] + np.array([-1, 1]) * d["Divorce SE"][i]
x = d.MedianAgeMarriage[i]
plt.plot([x, x], ci, "k")
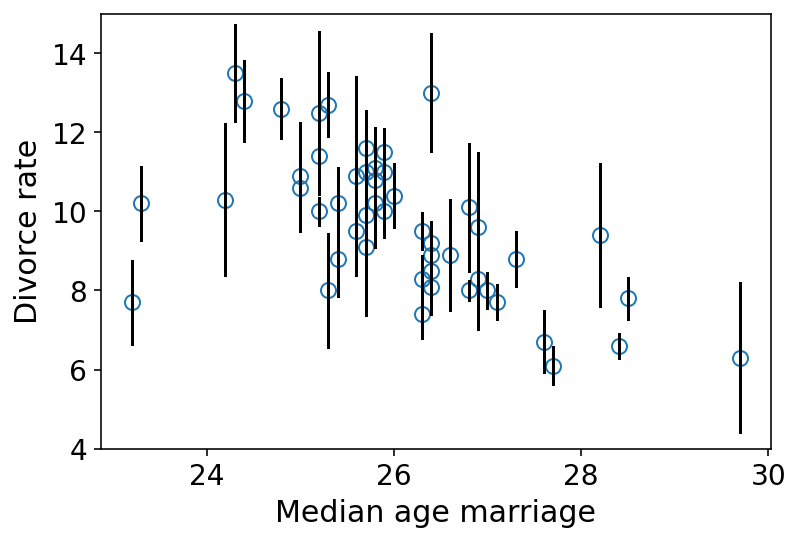
In the above plot, the lenght of the vertical lines show how uncertain the observed divorce rate is.
15.1.1 Error on the outcome¶
Code 15.3¶
d["D_obs"] = d.Divorce.pipe(lambda x: (x - x.mean()) / x.std()).values
d["D_sd"] = d["Divorce SE"].values / d.Divorce.std()
d["M"] = d.Marriage.pipe(lambda x: (x - x.mean()) / x.std()).values
d["A"] = d.MedianAgeMarriage.pipe(lambda x: (x - x.mean()) / x.std()).values
N = d.shape[0]
tdf = dataframe_to_tensors("Waffle", d, ["D_obs", "D_sd", "M", "A"])
def model_15_1(A, M, D_sd, N):
def _generator():
alpha = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=0.2, name="alpha"), sample_shape=1)
)
betaA = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=0.5, name="betaA"), sample_shape=1)
)
betaM = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=0.5, name="betaM"), sample_shape=1)
)
sigma = yield Root(
tfd.Sample(tfd.Exponential(rate=1.0, name="sigma"), sample_shape=1)
)
mu = (
alpha[..., tf.newaxis]
+ betaA[..., tf.newaxis] * A
+ betaM[..., tf.newaxis] * M
)
scale = sigma[..., tf.newaxis]
D_true = yield tfd.Independent(
tfd.Normal(loc=mu, scale=scale), reinterpreted_batch_ndims=1
)
D_obs = yield tfd.Independent(
tfd.Normal(loc=D_true, scale=D_sd), reinterpreted_batch_ndims=1
)
return tfd.JointDistributionCoroutine(_generator, validate_args=False)
jdc_15_1 = model_15_1(tdf.A, tdf.M, tdf.D_sd, N)
NUM_CHAINS_FOR_15_1 = 2
init_state = [
tf.zeros([NUM_CHAINS_FOR_15_1]),
tf.zeros([NUM_CHAINS_FOR_15_1]),
tf.zeros([NUM_CHAINS_FOR_15_1]),
tf.ones([NUM_CHAINS_FOR_15_1]),
tf.zeros([NUM_CHAINS_FOR_15_1, N]),
]
bijectors = [tfb.Identity(), tfb.Identity(), tfb.Identity(), tfb.Exp(), tfb.Identity()]
posterior_15_1, trace_15_1 = sample_posterior(
jdc_15_1,
observed_data=(tdf.D_obs,),
params=["alpha", "betaA", "betaM", "sigma", "D_true"],
init_state=init_state,
bijectors=bijectors,
)
Code 15.4¶
az.summary(trace_15_1, round_to=2, kind="all", hdi_prob=0.89)
| mean | sd | hdi_5.5% | hdi_94.5% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| alpha | -0.06 | 0.10 | -0.22 | 0.08 | 0.01 | 0.01 | 109.05 | 200.91 | 1.01 |
| betaA | -0.63 | 0.16 | -0.92 | -0.40 | 0.02 | 0.02 | 53.13 | 93.19 | 1.03 |
| betaM | 0.04 | 0.19 | -0.25 | 0.31 | 0.04 | 0.03 | 18.45 | 59.74 | 1.09 |
| sigma | 0.60 | 0.11 | 0.39 | 0.73 | 0.01 | 0.01 | 66.90 | 117.36 | 1.02 |
| D_true[0] | 1.26 | 0.35 | 0.75 | 1.85 | 0.03 | 0.02 | 117.35 | 180.86 | 1.00 |
| D_true[1] | 0.70 | 0.60 | -0.28 | 1.65 | 0.10 | 0.08 | 39.28 | 136.38 | 1.06 |
| D_true[2] | 0.42 | 0.35 | -0.11 | 0.99 | 0.05 | 0.03 | 55.38 | 213.89 | 1.03 |
| D_true[3] | 1.41 | 0.45 | 0.59 | 2.04 | 0.06 | 0.04 | 53.00 | 131.97 | 1.01 |
| D_true[4] | -0.90 | 0.13 | -1.11 | -0.71 | 0.00 | 0.00 | 868.33 | 360.15 | 1.02 |
| D_true[5] | 0.66 | 0.42 | -0.03 | 1.30 | 0.06 | 0.05 | 43.93 | 90.33 | 1.05 |
| D_true[6] | -1.41 | 0.36 | -2.06 | -0.92 | 0.03 | 0.02 | 136.04 | 230.52 | 1.01 |
| D_true[7] | -0.34 | 0.48 | -1.03 | 0.52 | 0.07 | 0.05 | 53.06 | 108.31 | 1.03 |
| D_true[8] | -1.85 | 0.57 | -2.83 | -0.99 | 0.10 | 0.07 | 34.20 | 63.60 | 1.06 |
| D_true[9] | -0.63 | 0.16 | -0.88 | -0.39 | 0.01 | 0.00 | 660.11 | 515.49 | 1.00 |
| D_true[10] | 0.75 | 0.28 | 0.25 | 1.14 | 0.02 | 0.02 | 151.34 | 263.64 | 1.00 |
| D_true[11] | -0.56 | 0.52 | -1.24 | 0.36 | 0.08 | 0.05 | 46.95 | 76.71 | 1.04 |
| D_true[12] | 0.14 | 0.49 | -0.67 | 0.88 | 0.07 | 0.05 | 51.70 | 59.41 | 1.03 |
| D_true[13] | -0.88 | 0.25 | -1.21 | -0.42 | 0.01 | 0.01 | 281.80 | 285.67 | 1.01 |
| D_true[14] | 0.58 | 0.28 | 0.15 | 1.03 | 0.02 | 0.01 | 261.25 | 352.47 | 1.01 |
| D_true[15] | 0.25 | 0.36 | -0.28 | 0.88 | 0.04 | 0.03 | 101.15 | 221.16 | 1.00 |
| D_true[16] | 0.48 | 0.46 | -0.23 | 1.20 | 0.06 | 0.04 | 68.56 | 149.62 | 1.04 |
| D_true[17] | 1.27 | 0.38 | 0.68 | 1.82 | 0.03 | 0.02 | 120.67 | 206.65 | 1.00 |
| D_true[18] | 0.43 | 0.41 | -0.18 | 1.11 | 0.09 | 0.06 | 26.83 | 91.41 | 1.09 |
| D_true[19] | 0.43 | 0.51 | -0.38 | 1.23 | 0.07 | 0.05 | 55.32 | 135.62 | 1.02 |
| D_true[20] | -0.61 | 0.32 | -1.15 | -0.14 | 0.03 | 0.02 | 153.39 | 319.71 | 1.01 |
| D_true[21] | -1.11 | 0.28 | -1.56 | -0.68 | 0.02 | 0.02 | 139.92 | 360.15 | 1.02 |
| D_true[22] | -0.31 | 0.26 | -0.66 | 0.19 | 0.02 | 0.01 | 281.42 | 236.17 | 1.02 |
| D_true[23] | -1.02 | 0.28 | -1.47 | -0.58 | 0.02 | 0.02 | 130.34 | 224.33 | 1.01 |
| D_true[24] | 0.38 | 0.39 | -0.24 | 0.98 | 0.08 | 0.06 | 24.13 | 93.51 | 1.10 |
| D_true[25] | -0.03 | 0.31 | -0.51 | 0.49 | 0.02 | 0.02 | 170.11 | 174.30 | 1.03 |
| D_true[26] | 0.10 | 0.52 | -0.71 | 0.93 | 0.10 | 0.07 | 27.14 | 32.60 | 1.07 |
| D_true[27] | -0.21 | 0.40 | -0.81 | 0.44 | 0.05 | 0.03 | 68.40 | 189.51 | 1.03 |
| D_true[28] | -0.19 | 0.56 | -1.04 | 0.67 | 0.09 | 0.06 | 36.82 | 133.02 | 1.04 |
| D_true[29] | -1.82 | 0.25 | -2.24 | -1.44 | 0.02 | 0.01 | 240.84 | 239.03 | 1.02 |
| D_true[30] | 0.16 | 0.39 | -0.41 | 0.78 | 0.04 | 0.03 | 95.82 | 176.83 | 1.01 |
| D_true[31] | -1.66 | 0.17 | -1.92 | -1.41 | 0.01 | 0.01 | 550.39 | 437.39 | 1.00 |
| D_true[32] | 0.13 | 0.25 | -0.26 | 0.52 | 0.02 | 0.01 | 209.86 | 300.99 | 1.01 |
| D_true[33] | -0.06 | 0.51 | -0.93 | 0.63 | 0.08 | 0.06 | 41.48 | 61.37 | 1.05 |
| D_true[34] | -0.11 | 0.23 | -0.49 | 0.24 | 0.01 | 0.01 | 315.77 | 198.17 | 1.01 |
| D_true[35] | 1.27 | 0.43 | 0.53 | 1.88 | 0.04 | 0.03 | 98.85 | 165.60 | 1.03 |
| D_true[36] | 0.22 | 0.36 | -0.38 | 0.76 | 0.03 | 0.03 | 109.23 | 142.62 | 1.01 |
| D_true[37] | -1.03 | 0.21 | -1.34 | -0.68 | 0.01 | 0.01 | 260.83 | 204.16 | 1.01 |
| D_true[38] | -0.94 | 0.59 | -2.00 | -0.11 | 0.11 | 0.08 | 29.56 | 112.37 | 1.05 |
| D_true[39] | -0.66 | 0.34 | -1.27 | -0.17 | 0.03 | 0.02 | 147.77 | 209.52 | 1.02 |
| D_true[40] | 0.37 | 0.55 | -0.45 | 1.29 | 0.07 | 0.05 | 59.30 | 149.61 | 1.03 |
| D_true[41] | 0.72 | 0.32 | 0.17 | 1.17 | 0.02 | 0.02 | 169.59 | 360.77 | 1.01 |
| D_true[42] | 0.18 | 0.20 | -0.11 | 0.50 | 0.01 | 0.01 | 451.58 | 280.05 | 1.00 |
| D_true[43] | 0.83 | 0.46 | 0.17 | 1.61 | 0.08 | 0.06 | 32.42 | 127.93 | 1.06 |
| D_true[44] | -0.44 | 0.56 | -1.33 | 0.44 | 0.11 | 0.08 | 24.94 | 64.86 | 1.09 |
| D_true[45] | -0.40 | 0.25 | -0.85 | -0.04 | 0.02 | 0.01 | 244.47 | 193.21 | 1.01 |
| D_true[46] | 0.12 | 0.30 | -0.33 | 0.60 | 0.02 | 0.01 | 224.57 | 391.40 | 1.00 |
| D_true[47] | 0.61 | 0.47 | -0.10 | 1.32 | 0.06 | 0.04 | 54.81 | 176.98 | 1.04 |
| D_true[48] | -0.63 | 0.27 | -1.06 | -0.22 | 0.02 | 0.01 | 268.48 | 303.84 | 1.01 |
| D_true[49] | 0.76 | 0.59 | -0.24 | 1.68 | 0.14 | 0.12 | 16.74 | 87.61 | 1.13 |
Code 15.5¶
What happens when there is a measurement error on predictor variables as well ?
d["D_obs"] = d.Divorce.pipe(lambda x: (x - x.mean()) / x.std()).values
d["D_sd"] = d["Divorce SE"].values / d.Divorce.std()
d["M_obs"] = d.Marriage.pipe(lambda x: (x - x.mean()) / x.std()).values
d["M_sd"] = d["Marriage SE"].values / d.Marriage.std()
d["A"] = d.MedianAgeMarriage.pipe(lambda x: (x - x.mean()) / x.std()).values
N = d.shape[0]
tdf = dataframe_to_tensors("Waffle", d, ["D_obs", "D_sd", "M_obs", "M_sd", "A"])
def model_15_2(A, M_sd, D_sd, N):
def _generator():
alpha = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=0.2, name="alpha"), sample_shape=1)
)
betaA = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=0.5, name="betaA"), sample_shape=1)
)
betaM = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=0.5, name="betaM"), sample_shape=1)
)
sigma = yield Root(
tfd.Sample(tfd.Exponential(rate=1.0, name="sigma"), sample_shape=1)
)
M_true = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=1.0, name="M_true"), sample_shape=N)
)
mu = (
alpha[..., tf.newaxis]
+ betaA[..., tf.newaxis] * A
+ betaM[..., tf.newaxis] * M_true
)
scale = sigma[..., tf.newaxis]
D_true = yield tfd.Independent(
tfd.Normal(loc=mu, scale=scale), reinterpreted_batch_ndims=1
)
D_obs = yield tfd.Independent(
tfd.Normal(loc=D_true, scale=D_sd), reinterpreted_batch_ndims=1
)
M_obs = yield tfd.Independent(
tfd.Normal(loc=M_true, scale=M_sd, name="M_obs"),
reinterpreted_batch_ndims=1,
)
return tfd.JointDistributionCoroutine(_generator, validate_args=False)
jdc_15_2 = model_15_2(tdf.A, tdf.M_sd, tdf.D_sd, N)
NUM_CHAINS_FOR_15_2 = 2
init_state = [
tf.zeros([NUM_CHAINS_FOR_15_2]),
tf.zeros([NUM_CHAINS_FOR_15_2]),
tf.zeros([NUM_CHAINS_FOR_15_2]),
tf.ones([NUM_CHAINS_FOR_15_2]),
tf.zeros([NUM_CHAINS_FOR_15_2, N]), # M_True
tf.zeros([NUM_CHAINS_FOR_15_2, N]), # D_True
]
bijectors = [
tfb.Identity(),
tfb.Identity(),
tfb.Identity(),
tfb.Exp(),
tfb.Identity(),
tfb.Identity(),
]
posterior_15_2, trace_15_2 = sample_posterior(
jdc_15_2,
observed_data=(tdf.D_obs, tdf.M_obs),
params=["alpha", "betaA", "betaM", "sigma", "M_true", "D_true"],
init_state=init_state,
bijectors=bijectors,
)
Code 15.6¶
post_D_true = trace_15_2.posterior["D_true"].values[0]
post_M_true = trace_15_2.posterior["M_true"].values[0]
D_est = np.mean(post_D_true, 0)
M_est = np.mean(post_M_true, 0)
plt.plot(d["M_obs"], d["D_obs"], "bo", alpha=0.5)
plt.gca().set(xlabel="marriage rate (std)", ylabel="divorce rate (std)")
plt.plot(M_est, D_est, "ko", mfc="none")
for i in range(d.shape[0]):
plt.plot([d["M_obs"][i], M_est[i]], [d["D_obs"][i], D_est[i]], "k-", lw=1)
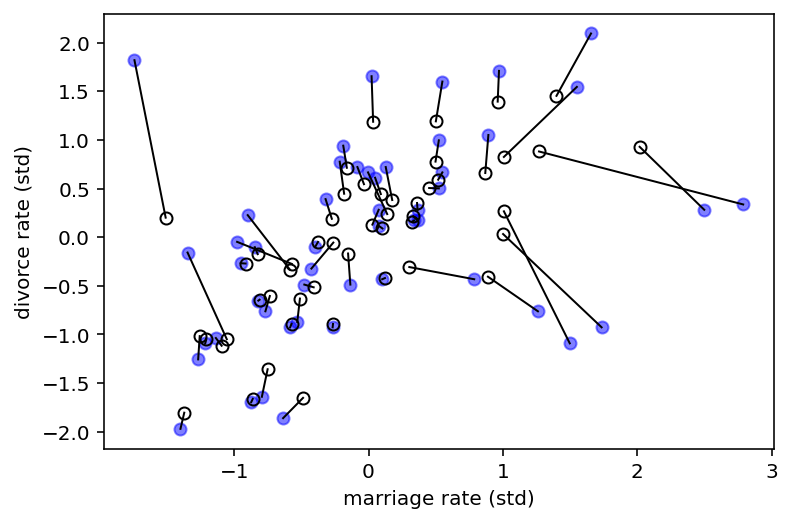
Above figure demonstrates shrinkage of both divorce rate and marriage rate. Solid points are the observed values. Open points are posterior means. Lines connect pairs of points for the same state. Both variables are shrunk towards the inferred regression relationship.
With measurement error, the insight is to realize that any uncertain piece of data can be replaced by a distribution that reflects uncertainty.
Code 15.7¶
# Simulated toy data
N = 500
A = tfd.Normal(loc=0.0, scale=1.0).sample((N,))
M = tfd.Normal(loc=-A, scale=1.0).sample()
D = tfd.Normal(loc=A, scale=1.0).sample()
A_obs = tfd.Normal(loc=A, scale=1.0).sample()
15.2 Missing data¶
15.2.1 DAG ate my homework¶
Code 15.8¶
N = 100
S = tfd.Normal(loc=0.0, scale=1.0).sample((N,))
H = tfd.Binomial(total_count=10, probs=tf.sigmoid(S)).sample()
Code 15.9¶
Hm = Homework missing
Dog’s decision to eat a piece of homework or not is not influenced by any relevant variable
D = tfd.Bernoulli(0.5).sample().numpy() # dogs completely random
Hm = np.where(D == 1, np.nan, H)
Hm
array([ 7., 1., 2., 4., 3., 5., 8., 6., 9., 5., 6., 4., 8.,
8., 8., 3., 2., 4., 1., 6., 3., 2., 1., 8., 6., 4.,
2., 1., 6., 5., 3., 4., 5., 1., 2., 7., 3., 8., 10.,
4., 9., 7., 5., 6., 3., 7., 0., 5., 5., 6., 5., 5.,
4., 3., 6., 5., 2., 4., 1., 3., 2., 3., 9., 6., 8.,
5., 9., 7., 2., 6., 5., 1., 3., 6., 1., 5., 1., 5.,
5., 1., 9., 9., 2., 8., 4., 6., 4., 1., 7., 5., 7.,
2., 7., 1., 4., 4., 7., 8., 1., 1.], dtype=float32)
Since missing values are random, missignness does not necessiarily change the overall distribution of homework score.
Code 15.10¶
Here studying influences whether a dog eats homework S->D
Students who study a lot do not play with their Dogs and then dogs take revenge by eating homework
D = np.where(S > 0, 1, 0)
Hm = np.where(D == 1, np.nan, H)
Hm
array([nan, 1., 2., nan, nan, nan, nan, nan, nan, 5., nan, 4., nan,
nan, nan, 3., 2., 4., 1., 6., nan, 2., 1., nan, nan, nan,
2., 1., nan, nan, 3., 4., nan, 1., 2., nan, 3., nan, nan,
4., nan, nan, nan, 6., 3., nan, 0., 5., 5., 6., 5., 5.,
nan, 3., 6., nan, 2., 4., 1., 3., 2., 3., nan, 6., nan,
nan, nan, nan, 2., nan, 5., 1., 3., nan, 1., nan, 1., nan,
nan, 1., nan, nan, 2., nan, 4., nan, nan, 1., nan, 5., nan,
2., 7., 1., 4., 4., nan, nan, 1., 1.], dtype=float32)
Now every student who studies more than average (0) is missing homework
Code 15.11¶
The case of noisy home and its influence on homework & Dog’s behavior
# TODO - use seed; have not been able to make it work with tfp
N = 1000
X = tfd.Sample(tfd.Normal(loc=0.0, scale=1.0), sample_shape=(N,)).sample().numpy()
S = tfd.Sample(tfd.Normal(loc=0.0, scale=1.0), sample_shape=(N,)).sample().numpy()
logits = 2 + S - 2 * X
H = tfd.Binomial(total_count=10, logits=logits).sample().numpy()
D = np.where(X > 1, 1, 0)
Hm = np.where(D == 1, np.nan, H)
Code 15.12¶
tdf = dataframe_to_tensors(
"SimulatedHomeWork", pd.DataFrame.from_dict(dict(H=H, S=S)), ["H", "S"]
)
def model_15_3(S):
def _generator():
alpha = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=1.0, name="alpha"), sample_shape=1)
)
betaS = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=0.5, name="betaS"), sample_shape=1)
)
logits = tf.squeeze(alpha[..., tf.newaxis] + betaS[..., tf.newaxis] * S)
H = yield tfd.Independent(
tfd.Binomial(total_count=10, logits=logits), reinterpreted_batch_ndims=1
)
return tfd.JointDistributionCoroutine(_generator, validate_args=False)
jdc_15_3 = model_15_3(tdf.S)
NUM_CHAINS_FOR_15_3 = 4
alpha_init, betaS_init, _ = jdc_15_3.sample()
init_state = [
tf.tile(alpha_init, (NUM_CHAINS_FOR_15_3,)),
tf.tile(betaS_init, (NUM_CHAINS_FOR_15_3,)),
]
bijectors = [
tfb.Identity(),
tfb.Identity(),
]
posterior_15_3, trace_15_3 = sample_posterior(
jdc_15_3,
observed_data=(tdf.H,),
params=["alpha", "betaS"],
init_state=init_state,
bijectors=bijectors,
)
WARNING:tensorflow:@custom_gradient grad_fn has 'variables' in signature, but no ResourceVariables were used on the forward pass.
az.summary(trace_15_3, round_to=2, kind="all", hdi_prob=0.89)
| mean | sd | hdi_5.5% | hdi_94.5% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| alpha | 1.11 | 0.02 | 1.07 | 1.15 | 0.0 | 0.0 | 113.07 | 147.35 | 1.03 |
| betaS | 0.62 | 0.02 | 0.58 | 0.66 | 0.0 | 0.0 | 113.80 | 156.06 | 1.03 |
The true coefficient on S should be 1.00. We don’t expect to get that exactly, but the estimate above is way off
Code 15.13¶
We build the model with missing data now
tdf = dataframe_to_tensors(
"SimulatedHomeWork",
pd.DataFrame.from_dict(dict(H=H[D == 0], S=S[D == 0])),
["H", "S"],
)
def model_15_4(S):
def _generator():
alpha = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=1.0, name="alpha"), sample_shape=1)
)
betaS = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=0.5, name="betaS"), sample_shape=1)
)
logits = tf.squeeze(alpha[..., tf.newaxis] + betaS[..., tf.newaxis] * S)
H = yield tfd.Independent(
tfd.Binomial(total_count=10, logits=logits), reinterpreted_batch_ndims=1
)
return tfd.JointDistributionCoroutine(_generator, validate_args=False)
jdc_15_4 = model_15_4(tdf.S)
NUM_CHAINS_FOR_15_4 = 2
alpha_init, betaS_init, _ = jdc_15_4.sample()
init_state = [
tf.tile(alpha_init, (NUM_CHAINS_FOR_15_4,)),
tf.tile(betaS_init, (NUM_CHAINS_FOR_15_4,)),
]
bijectors = [
tfb.Identity(),
tfb.Identity(),
]
posterior_15_4, trace_15_4 = sample_posterior(
jdc_15_4,
observed_data=(tdf.H,),
params=["alpha", "betaS"],
init_state=init_state,
bijectors=bijectors,
)
WARNING:tensorflow:@custom_gradient grad_fn has 'variables' in signature, but no ResourceVariables were used on the forward pass.
az.summary(trace_15_4, round_to=2, kind="all", hdi_prob=0.89)
| mean | sd | hdi_5.5% | hdi_94.5% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| alpha | 1.8 | 0.03 | 1.75 | 1.85 | 0.0 | 0.0 | 619.78 | 413.92 | 1.01 |
| betaS | 0.8 | 0.03 | 0.75 | 0.85 | 0.0 | 0.0 | 691.86 | 552.62 | 1.00 |
Code 15.14¶
D = np.where(np.abs(X) < 1, 1, 0)
Code 15.15¶
N = 100
S = tfd.Normal(loc=0.0, scale=1.0).sample((N,))
H = tfd.Binomial(total_count=10, logits=S).sample().numpy()
D = np.where(H < 5, 1, 0)
Hm = np.where(D == 1, np.nan, H)
Hm
array([ 5., 5., 6., 6., 6., 5., nan, 6., 8., 6., nan, 7., 5.,
7., 5., 7., nan, 6., 10., 9., nan, 7., 9., nan, nan, nan,
10., 7., nan, nan, 6., 8., nan, nan, 6., nan, 5., 7., nan,
7., 5., 8., 9., nan, nan, nan, nan, nan, 7., nan, nan, 8.,
nan, 10., 6., 9., 8., 5., nan, 7., nan, nan, nan, 7., nan,
5., nan, 5., nan, 8., nan, 7., nan, 5., 8., nan, 7., 6.,
nan, nan, nan, 8., nan, 7., 8., 6., nan, nan, 7., 8., nan,
7., 6., 8., nan, 7., 6., nan, nan, 5.], dtype=float32)