7. Ulysses’ Compass
Contents
![]()
7. Ulysses’ Compass¶
# Install packages that are not installed in colab
try:
import google.colab
%pip install -q watermark
%pip install git+https://github.com/ksachdeva/rethinking-tensorflow-probability.git
except:
pass
%load_ext watermark
# Core
from io import StringIO
import numpy as np
import arviz as az
import pandas as pd
import xarray as xr
import tensorflow as tf
import tensorflow_probability as tfp
import statsmodels.formula.api as smf
# visualization
import matplotlib.pyplot as plt
from rethinking.data import RethinkingDataset
from rethinking.data import dataframe_to_tensors
from rethinking.mcmc import sample_posterior
# aliases
tfd = tfp.distributions
tfb = tfp.bijectors
Root = tfd.JointDistributionCoroutine.Root
2022-01-19 18:58:38.259738: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory
2022-01-19 18:58:38.259789: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
%watermark -p numpy,tensorflow,tensorflow_probability,arviz,scipy,pandas
numpy : 1.21.5
tensorflow : 2.7.0
tensorflow_probability: 0.15.0
arviz : 0.11.4
scipy : 1.7.3
pandas : 1.3.5
# config of various plotting libraries
%config InlineBackend.figure_format = 'retina'
7.1 The problem with parameters¶
7.1.1 More parameters(almost) always improve fit¶
Code 7.1¶
Below is a dataset for average brain volumes and body masses for 7 hominin species
sppnames = [
"afarensis",
"africanus",
"habilis",
"boisei",
"rudolfensis",
"ergaster",
"sapiens",
]
brainvolcc = np.array([438, 452, 612, 521, 752, 871, 1350])
masskg = np.array([37.0, 35.5, 34.5, 41.5, 55.5, 61.0, 53.5])
d = pd.DataFrame({"species": sppnames, "brain": brainvolcc, "mass": masskg})
d
| species | brain | mass | |
|---|---|---|---|
| 0 | afarensis | 438 | 37.0 |
| 1 | africanus | 452 | 35.5 |
| 2 | habilis | 612 | 34.5 |
| 3 | boisei | 521 | 41.5 |
| 4 | rudolfensis | 752 | 55.5 |
| 5 | ergaster | 871 | 61.0 |
| 6 | sapiens | 1350 | 53.5 |
# Reproducing the figure in the book (there is no code fragment for this in R in the book)
plt.scatter(d.mass, d.brain, facecolors="none", edgecolors="b")
plt.gca().set(
xlim=(30, 70), xlabel="body mass (kg)", ylim=(400, 1400), ylabel="brain volume (cc)"
)
for i in range(d.shape[0]):
plt.annotate(d.species[i], (d.mass[i], d.brain[i]))
plt.tight_layout();

Code 7.2¶
Author talks about linear vs polynomial regression. He is of the opinion that most of the time polynomial regression is not a good idea (at least when used blindly). But why ?
d["mass_std"] = (d.mass - d.mass.mean()) / d.mass.std()
d["brain_std"] = d.brain / d.brain.max()
tdf = dataframe_to_tensors("Brain", d, ["mass_std", "brain_std"])
2022-01-19 18:58:41.170232: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcuda.so.1'; dlerror: libcuda.so.1: cannot open shared object file: No such file or directory
2022-01-19 18:58:41.170269: W tensorflow/stream_executor/cuda/cuda_driver.cc:269] failed call to cuInit: UNKNOWN ERROR (303)
2022-01-19 18:58:41.170295: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:156] kernel driver does not appear to be running on this host (fv-az272-145): /proc/driver/nvidia/version does not exist
2022-01-19 18:58:41.170635: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
Note - brain is not standardized as such because you can not have -ive brain
Code 7.3¶
Simplest model is the linear one and this is what we will start with
def model_7_1(mass_std):
def _generator():
alpha = yield Root(
tfd.Sample(tfd.Normal(loc=0.5, scale=1.0, name="alpha"), sample_shape=1)
)
beta = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=10.0, name="beta"), sample_shape=1)
)
sigma = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=1.0, name="sigma"), sample_shape=1)
)
mu = alpha[..., tf.newaxis] + beta[..., tf.newaxis] * mass_std
scale = sigma[..., tf.newaxis]
brain_std = yield tfd.Independent(
tfd.Normal(loc=mu, scale=tf.exp(scale)), reinterpreted_batch_ndims=1
)
return tfd.JointDistributionCoroutine(_generator, validate_args=False)
jdc_7_1 = model_7_1(tdf.mass_std)
NUMBER_OF_CHAINS = 2
init_state = [
0.5 * tf.ones([NUMBER_OF_CHAINS]),
tf.zeros([NUMBER_OF_CHAINS]),
tf.zeros([NUMBER_OF_CHAINS]),
]
bijectors = [
tfb.Identity(),
tfb.Identity(),
tfb.Identity(),
]
jdc = jdc_7_1
observed_data = (tdf.brain_std,)
posterior_7_1, trace_7_1 = sample_posterior(
jdc,
observed_data=observed_data,
params=["alpha", "beta", "sigma"],
num_samples=5000,
burnin=1000,
init_state=init_state,
bijectors=bijectors,
)
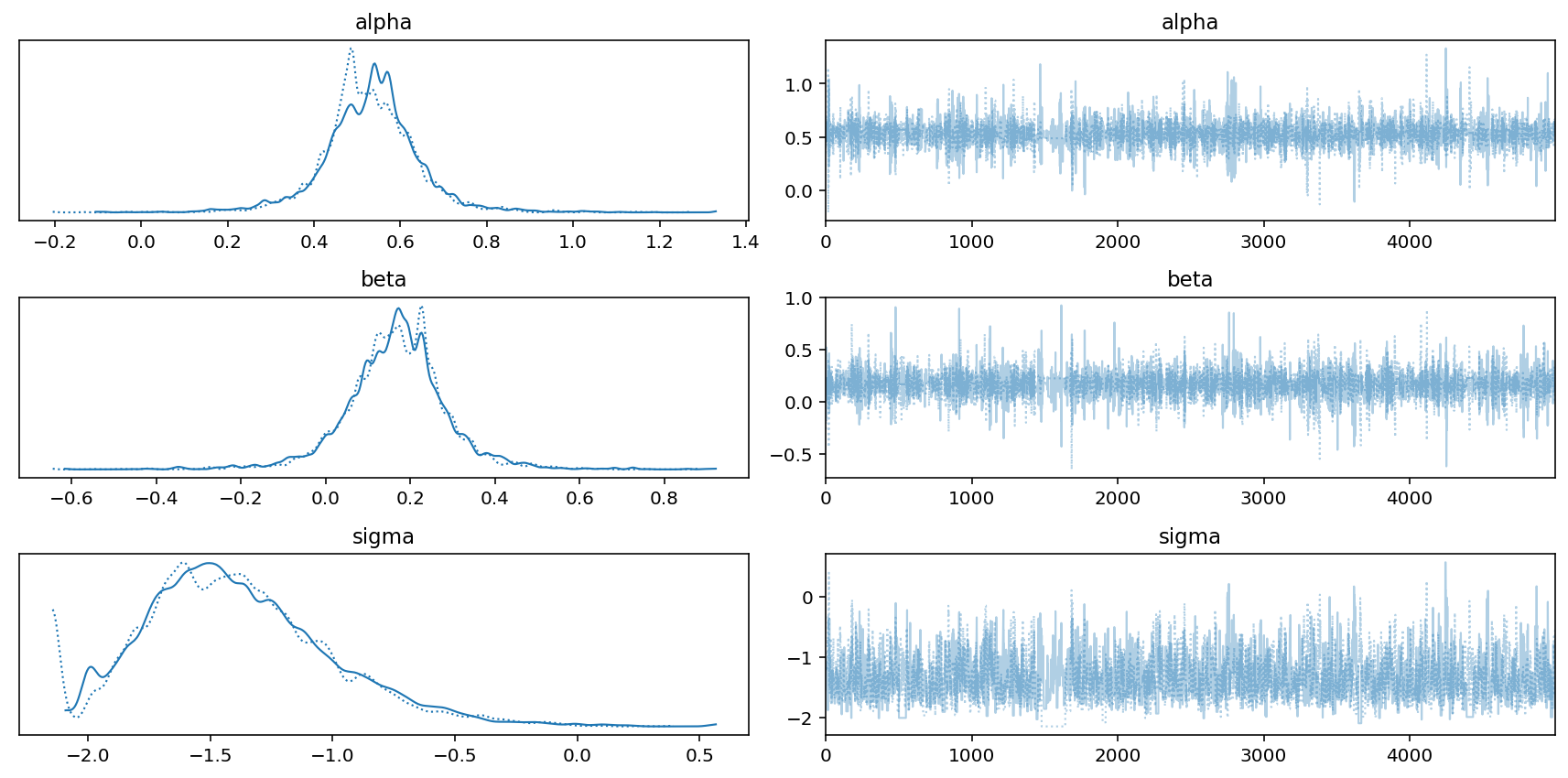
az.summary(trace_7_1, hdi_prob=0.89)
| mean | sd | hdi_5.5% | hdi_94.5% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| alpha | 0.530 | 0.112 | 0.370 | 0.697 | 0.002 | 0.001 | 4378.0 | 2497.0 | 1.0 |
| beta | 0.166 | 0.120 | -0.005 | 0.348 | 0.002 | 0.001 | 4416.0 | 3087.0 | 1.0 |
| sigma | -1.387 | 0.380 | -2.012 | -0.846 | 0.016 | 0.014 | 413.0 | 171.0 | 1.0 |
az.plot_trace(trace_7_1)
plt.tight_layout();
Code 7.4¶
OLS and Bayesian anti-essentialism.
Use OLS for the above model. Author has used R’s lm package so here we are using statsmodel (..sort of python counterpart to R’s lm package) to do oridinary least square.
The OLS from the non bayesian statistics is going to provide the point estimates (which would to some extent correspond to the mean (mu) if flat priors are used).
Note - In the text book you would see
m7.1_OLS <- lm( brain_std ~ mass_std , data=d )
post <- extract.samples( m7.1_OLS )
extract.samples( m7.1_OLS ) is in the source file https://github.com/rmcelreath/rethinking/blob/master/R/map-quap-class.r
Below I have replicated the code for extract.samples for (non-bayesian OLS) using statsmodel & tensorflow probabilty
# Use statsmodel OLS
m_7_1_OLS = smf.ols("brain_std ~ mass_std", data=d).fit()
m_7_1_OLS.params, m_7_1_OLS.cov_params()
(Intercept 0.528677
mass_std 0.167118
dtype: float64,
Intercept mass_std
Intercept 4.980017e-03 3.981467e-19
mass_std 3.981467e-19 5.810020e-03)
# Get the mean of the two parameters (intercept & coefficient for mass_std)
# and create the mu tensor
mu = tf.constant(m_7_1_OLS.params, dtype=tf.float32)
# Get the variance-covariance matrix and create the cov tensor
cov = tf.constant(m_7_1_OLS.cov_params(), dtype=tf.float32)
# we can build a multivariate normal distribution using the mu & cov obtained
# from the non bayesian land
mvn = tfd.MultivariateNormalTriL(loc=mu, scale_tril=tf.linalg.cholesky(cov))
posterior = mvn.sample(10000)
Code 7.5¶
Variance explained or \(R^2\) is defined as:
\(R^2\) = 1 - \(\frac{var(residuals)}{var(outcome)}\)
# We will have to simulate (compute) our posterior brain_std from the samples
sample_alpha = posterior_7_1["alpha"]
sample_beta = posterior_7_1["beta"]
sample_sigma = posterior_7_1["sigma"]
ds, samples = jdc_7_1.sample_distributions(
value=[sample_alpha, sample_beta, sample_sigma, None]
)
sample_brain_std = ds[-1].distribution.sample()
# get the mean
brain_std_mean = tf.reduce_mean(sample_brain_std, axis=1) # <--note usage of axis 1
r = brain_std_mean - d.brain_std.values
# compute the variance expained (R square)
resid_var = np.var(r, ddof=1)
outcome_var = np.var(d.brain_std.values, ddof=1)
1 - resid_var / outcome_var
0.5438988413731545
Code 7.6¶
\(R^2\) is bad, the author says ! … here is resuable function that will used multiple times later
def RX_is_bad(jdc, posterior, scale=None):
sample_alpha = posterior["alpha"]
sample_beta = posterior["beta"]
if scale is None:
sample_sigma = posterior["sigma"]
else:
sample_sigma = 0.001 # model number 6
ds, samples = jdc.sample_distributions(
value=[sample_alpha, sample_beta, sample_sigma, None]
)
sample_brain_std = ds[-1].distribution.sample()
# get the mean
brain_std_mean = tf.reduce_mean(sample_brain_std, axis=1) # <--note usage of axis 1
r = brain_std_mean - d.brain_std.values
# compute the variance expained (R square)
resid_var = np.var(r, ddof=1)
outcome_var = np.var(d.brain_std.values, ddof=1)
1 - resid_var / outcome_var
return 1 - resid_var / outcome_var
Code 7.7¶
Building some more models to compare to m7.1
This one is a poymomial of second degree
def model_7_2(mass_std):
def _generator():
alpha = yield Root(
tfd.Sample(tfd.Normal(loc=0.5, scale=1.0, name="alpha"), sample_shape=1)
)
beta = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=10.0, name="beta"), sample_shape=2)
)
sigma = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=1.0, name="sigma"), sample_shape=1)
)
beta1 = tf.squeeze(tf.gather(beta, [0], axis=-1))
beta2 = tf.squeeze(tf.gather(beta, [1], axis=-1))
mu = (
alpha[..., tf.newaxis]
+ beta1[..., tf.newaxis] * mass_std
+ beta2[..., tf.newaxis] * (mass_std ** 2)
)
scale = sigma[..., tf.newaxis]
brain_std = yield tfd.Independent(
tfd.Normal(loc=mu, scale=tf.exp(scale)), reinterpreted_batch_ndims=1
)
return tfd.JointDistributionCoroutine(_generator, validate_args=False)
# will use this method for various models
def compute_brain_body_posterior_for_simulation(beta_degree, jdc):
if beta_degree == 1:
init_state = [
0.5 * tf.ones([NUMBER_OF_CHAINS]),
tf.zeros([NUMBER_OF_CHAINS]),
tf.zeros([NUMBER_OF_CHAINS]),
]
else:
init_state = [
0.5 * tf.ones([NUMBER_OF_CHAINS]),
tf.zeros([NUMBER_OF_CHAINS, beta_degree]),
tf.zeros([NUMBER_OF_CHAINS]),
]
bijectors = [
tfb.Identity(),
tfb.Identity(),
tfb.Identity(),
]
observed_data = (tdf.brain_std,)
posterior, trace = sample_posterior(
jdc,
observed_data=observed_data,
params=["alpha", "beta", "sigma"],
num_samples=4000,
burnin=1000,
init_state=init_state,
bijectors=bijectors,
)
return posterior, trace
Code 7.8¶
Models of 3rd, 4th and 5th degrees
def model_7_3(mass_std):
def _generator():
alpha = yield Root(
tfd.Sample(tfd.Normal(loc=0.5, scale=1.0, name="alpha"), sample_shape=1)
)
beta = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=10.0, name="beta"), sample_shape=3)
)
sigma = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=1.0, name="sigma"), sample_shape=1)
)
beta1 = tf.squeeze(tf.gather(beta, [0], axis=-1))
beta2 = tf.squeeze(tf.gather(beta, [1], axis=-1))
beta3 = tf.squeeze(tf.gather(beta, [2], axis=-1))
mu = (
alpha[..., tf.newaxis]
+ beta1[..., tf.newaxis] * mass_std
+ beta2[..., tf.newaxis] * (mass_std ** 2)
+ beta3[..., tf.newaxis] * (mass_std ** 3)
)
scale = sigma[..., tf.newaxis]
brain_std = yield tfd.Independent(
tfd.Normal(loc=mu, scale=tf.exp(scale)), reinterpreted_batch_ndims=1
)
return tfd.JointDistributionCoroutine(_generator, validate_args=False)
def model_7_4(mass_std):
def _generator():
alpha = yield Root(
tfd.Sample(tfd.Normal(loc=0.5, scale=1.0, name="alpha"), sample_shape=1)
)
beta = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=10.0, name="beta"), sample_shape=4)
)
sigma = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=1.0, name="sigma"), sample_shape=1)
)
beta1 = tf.squeeze(tf.gather(beta, [0], axis=-1))
beta2 = tf.squeeze(tf.gather(beta, [1], axis=-1))
beta3 = tf.squeeze(tf.gather(beta, [2], axis=-1))
beta4 = tf.squeeze(tf.gather(beta, [3], axis=-1))
mu = (
alpha[..., tf.newaxis]
+ beta1[..., tf.newaxis] * mass_std
+ beta2[..., tf.newaxis] * (mass_std ** 2)
+ beta3[..., tf.newaxis] * (mass_std ** 3)
+ beta4[..., tf.newaxis] * (mass_std ** 4)
)
scale = sigma[..., tf.newaxis]
brain_std = yield tfd.Independent(
tfd.Normal(loc=mu, scale=tf.exp(scale)), reinterpreted_batch_ndims=1
)
return tfd.JointDistributionCoroutine(_generator, validate_args=False)
def model_7_5(mass_std):
def _generator():
alpha = yield Root(
tfd.Sample(tfd.Normal(loc=0.5, scale=1.0, name="alpha"), sample_shape=1)
)
beta = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=10.0, name="beta"), sample_shape=5)
)
sigma = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=1.0, name="sigma"), sample_shape=1)
)
beta1 = tf.squeeze(tf.gather(beta, [0], axis=-1))
beta2 = tf.squeeze(tf.gather(beta, [1], axis=-1))
beta3 = tf.squeeze(tf.gather(beta, [2], axis=-1))
beta4 = tf.squeeze(tf.gather(beta, [3], axis=-1))
beta5 = tf.squeeze(tf.gather(beta, [4], axis=-1))
mu = (
alpha[..., tf.newaxis]
+ beta1[..., tf.newaxis] * mass_std
+ beta2[..., tf.newaxis] * (mass_std ** 2)
+ beta3[..., tf.newaxis] * (mass_std ** 3)
+ beta4[..., tf.newaxis] * (mass_std ** 4)
+ beta5[..., tf.newaxis] * (mass_std ** 5)
)
scale = sigma[..., tf.newaxis]
brain_std = yield tfd.Independent(
tfd.Normal(loc=mu, scale=tf.exp(scale)), reinterpreted_batch_ndims=1
)
return tfd.JointDistributionCoroutine(_generator, validate_args=False)
Code 7.9¶
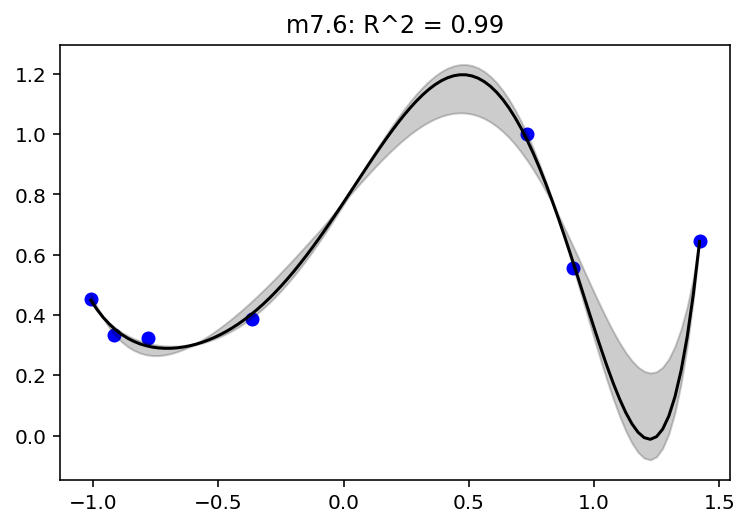
This one is of degree 6 but the standard deviation has been replaced with constant 0.001. The author mentions that otherwise it will not work and will be explained with the help of plot later
def model_7_6(mass_std):
def _generator():
alpha = yield Root(
tfd.Sample(tfd.Normal(loc=0.5, scale=1.0, name="alpha"), sample_shape=1)
)
beta = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=10.0, name="beta"), sample_shape=6)
)
beta1 = tf.squeeze(tf.gather(beta, [0], axis=-1))
beta2 = tf.squeeze(tf.gather(beta, [1], axis=-1))
beta3 = tf.squeeze(tf.gather(beta, [2], axis=-1))
beta4 = tf.squeeze(tf.gather(beta, [3], axis=-1))
beta5 = tf.squeeze(tf.gather(beta, [4], axis=-1))
beta6 = tf.squeeze(tf.gather(beta, [5], axis=-1))
mu = (
alpha[..., tf.newaxis]
+ beta1[..., tf.newaxis] * mass_std
+ beta2[..., tf.newaxis] * (mass_std ** 2)
+ beta3[..., tf.newaxis] * (mass_std ** 3)
+ beta4[..., tf.newaxis] * (mass_std ** 4)
+ beta5[..., tf.newaxis] * (mass_std ** 5)
+ beta6[..., tf.newaxis] * (mass_std ** 6)
)
brain_std = yield tfd.Independent(
tfd.Normal(loc=mu, scale=0.001), reinterpreted_batch_ndims=1
)
return tfd.JointDistributionCoroutine(_generator, validate_args=False)
# for this method we need to compute the posterior differently as the model is different in terms of params
def compute_posterior_for_76_simulation(jdc_7_6):
init_state = [0.5 * tf.ones([NUMBER_OF_CHAINS]), tf.zeros([NUMBER_OF_CHAINS, 6])]
bijectors = [tfb.Identity(), tfb.Identity()]
observed_data = (tdf.brain_std,)
posterior_7_6, trace_7_6 = sample_posterior(
jdc_7_6,
observed_data=observed_data,
params=["alpha", "beta"],
num_samples=4000,
burnin=1000,
init_state=init_state,
bijectors=bijectors,
)
return posterior_7_6, trace_7_6
Code 7.10¶
jdc_7_1 = model_7_1(tdf.mass_std)
jdc_7_2 = model_7_2(tdf.mass_std)
jdc_7_3 = model_7_3(tdf.mass_std)
jdc_7_4 = model_7_4(tdf.mass_std)
jdc_7_5 = model_7_5(tdf.mass_std)
jdc_7_6 = model_7_6(tdf.mass_std)
posterior_7_1, trace_7_1 = compute_brain_body_posterior_for_simulation(1, jdc_7_1)
posterior_7_2, trace_7_2 = compute_brain_body_posterior_for_simulation(2, jdc_7_2)
posterior_7_3, trace_7_3 = compute_brain_body_posterior_for_simulation(3, jdc_7_3)
posterior_7_4, trace_7_4 = compute_brain_body_posterior_for_simulation(4, jdc_7_4)
posterior_7_5, trace_7_5 = compute_brain_body_posterior_for_simulation(5, jdc_7_5)
posterior_7_6, trace_7_6 = compute_posterior_for_76_simulation(jdc_7_6)
WARNING:tensorflow:5 out of the last 5 calls to <function run_hmc_chain at 0x7f68c91d4cb0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
WARNING:tensorflow:6 out of the last 6 calls to <function run_hmc_chain at 0x7f68c91d4cb0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
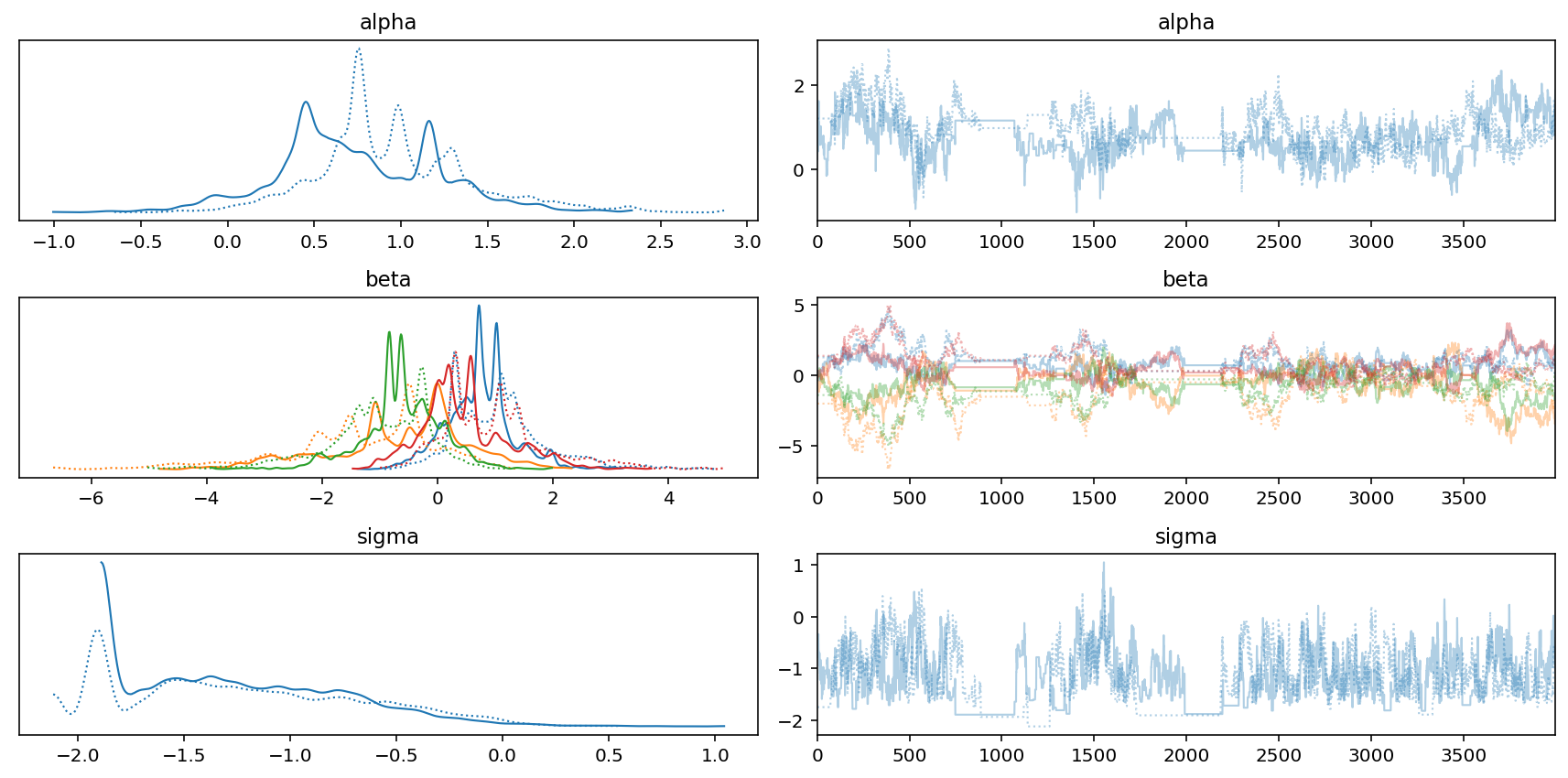
az.plot_trace(trace_7_4)
plt.tight_layout();
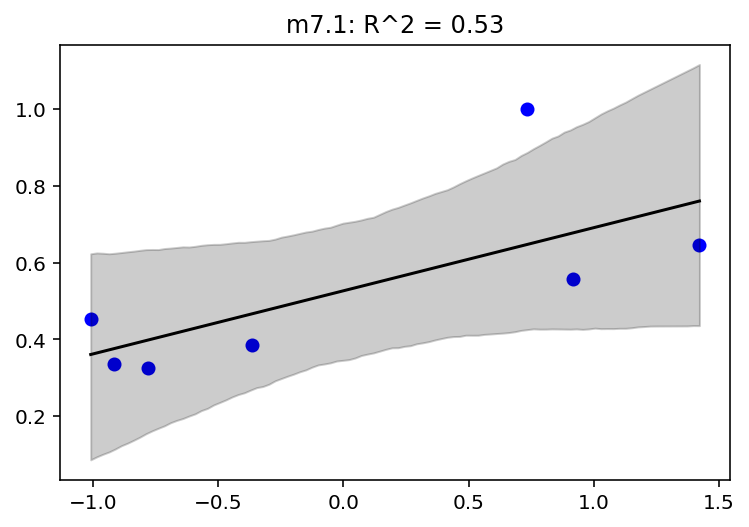
mass_seq = np.linspace(d.mass_std.min(), d.mass_std.max(), num=100)
def plot_model_mean(model_name, jdc, posterior, jdc_mass_seq):
if not "sigma" in posterior:
scale = 0.001 # model number 6
else:
scale = None
plt.title(
"{}: R^2 = {:0.2f}".format(model_name, RX_is_bad(jdc, posterior, scale).item())
)
sample_alpha = posterior["alpha"]
sample_beta = posterior["beta"]
if scale is None:
sample_sigma = posterior["sigma"]
else:
sample_sigma = 0.001 # model number 6
# jdc_mass_seq is the new joint distribution model
# that uses mass_seq as the data
#
# Note - we are using posteriors from
# the trace of jdc that we built earlier
ds, samples = jdc_mass_seq.sample_distributions(
value=[sample_alpha, sample_beta, sample_sigma, None]
)
# we get mu from the loc parameter of underlying
# distribution which is Normal
mu = ds[-1].distribution.loc
mu_mean = tf.reduce_mean(mu, 1)
mu_ci = tfp.stats.percentile(mu[0], (4.5, 95.5), 0)
plt.scatter(d.mass_std, d.brain_std, facecolors="b", edgecolors="b")
plt.plot(mass_seq, mu_mean[0], "k")
plt.fill_between(mass_seq, mu_ci[0], mu_ci[1], color="k", alpha=0.2)
jdc_7_1_mass_seq = model_7_1(mass_seq)
plot_model_mean("m7.1", jdc_7_1, posterior_7_1, jdc_7_1_mass_seq)
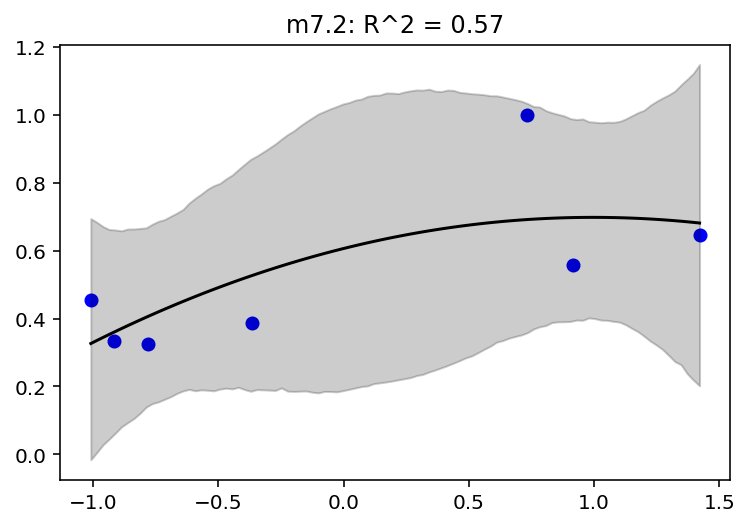
# Book does not provide the code snippet for other models but has corresponding figures so I am
# doing that as well
jdc_7_2_mass_seq = model_7_2(mass_seq)
plot_model_mean("m7.2", jdc_7_2, posterior_7_2, jdc_7_2_mass_seq)
jdc_7_3_mass_seq = model_7_3(mass_seq)
plot_model_mean("m7.3", jdc_7_3, posterior_7_3, jdc_7_3_mass_seq)
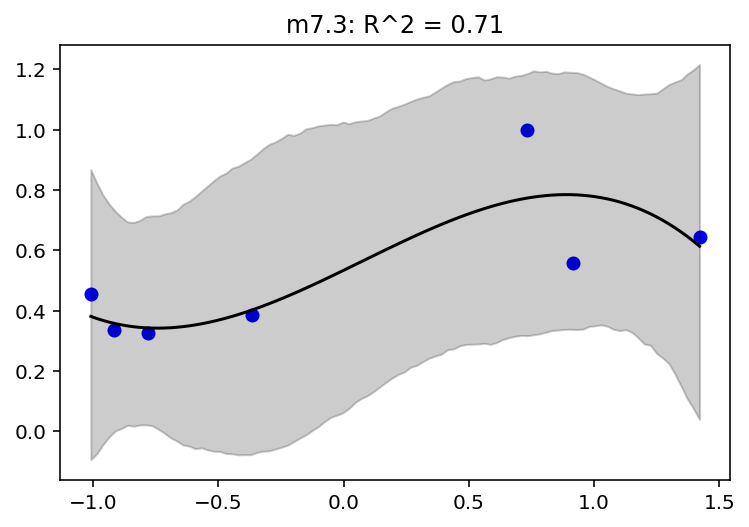
jdc_7_4_mass_seq = model_7_4(mass_seq)
plot_model_mean("m7.4", jdc_7_4, posterior_7_4, jdc_7_4_mass_seq)
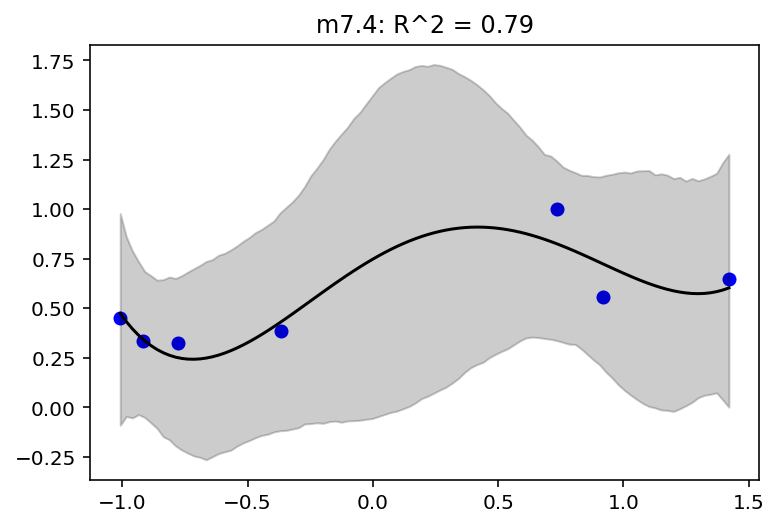
jdc_7_5_mass_seq = model_7_5(mass_seq)
plot_model_mean("m7.5", jdc_7_5, posterior_7_5, jdc_7_5_mass_seq)
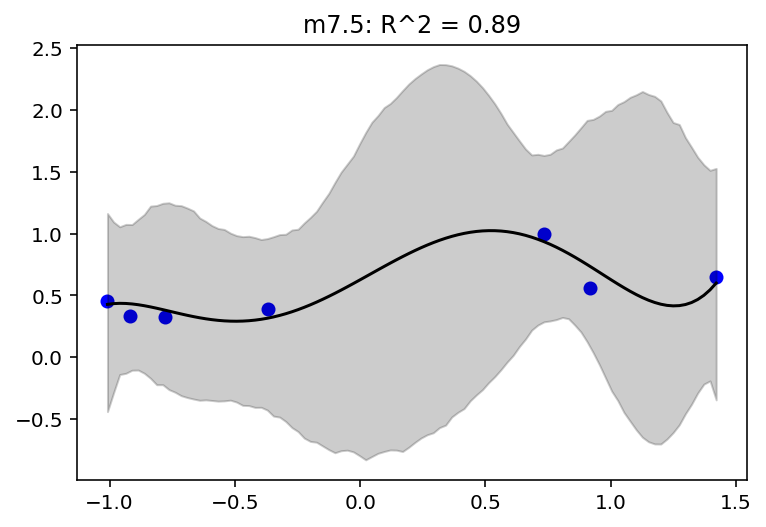
jdc_7_6_mass_seq = model_7_6(mass_seq)
plot_model_mean("m7.6", jdc_7_6, posterior_7_6, jdc_7_6_mass_seq)
7.2 Entropy and accuracy¶
7.2.1 Firing the weatherperson¶
7.2.2 Information and uncertainity¶
Code 7.12¶
p = np.array([0.3, 0.7])
-np.sum(p * np.log(p))
0.6108643020548935
7.2.3 From entropy to accuracy¶
7.2.4 Estimating divergence¶
Code 7.13¶
def compute_log_likelihood(jdc, posterior, trace, scale=None):
sample_alpha = posterior["alpha"]
sample_beta = posterior["beta"]
if scale is None:
sample_sigma = posterior["sigma"]
else:
sample_sigma = 0.001 # model number 6
ds, samples = jdc.sample_distributions(
value=[sample_alpha, sample_beta, sample_sigma, None]
)
log_likelihood_total = ds[-1].distribution.log_prob(tdf.brain_std).numpy()
# we are inserting the log likelihood in the trace
# as well though not required for this exercise
sample_stats = trace.sample_stats
coords = [sample_stats.coords["chain"], sample_stats.coords["draw"], np.arange(7)]
sample_stats["log_likelihood"] = xr.DataArray(
log_likelihood_total,
coords=coords,
dims=["chain", "draw", "log_likelihood_dim_0"],
)
print(log_likelihood_total.shape)
return log_likelihood_total
def lppd_fn(jdc, posterior, trace, scale=None):
ll = compute_log_likelihood(jdc, posterior, trace, scale)
ll = tf.math.reduce_logsumexp(ll, 0) - tf.math.log(
tf.cast(ll.shape[0], dtype=tf.float32)
)
return np.mean(ll, 0)
lppd_fn(jdc_7_1, posterior_7_1, trace_7_1)
(2, 4000, 7)
array([ 0.34390992, 0.37090367, 0.29685163, 0.36782235, 0.23993465,
0.18679237, -0.77394867], dtype=float32)
Overthinking¶
Code 7.14¶
This is simply an implementation of lppd_fn which I have done in 7.13 already
Scoring the right data¶
Code 7.15¶
ite = (
(jdc_7_1, posterior_7_1, trace_7_1),
(jdc_7_2, posterior_7_2, trace_7_2),
(jdc_7_3, posterior_7_3, trace_7_3),
(jdc_7_4, posterior_7_4, trace_7_4),
(jdc_7_5, posterior_7_5, trace_7_5),
)
[np.sum(lppd_fn(m[0], m[1], m[2])) for m in ite]
(2, 4000, 7)
(2, 4000, 7)
(2, 4000, 7)
(2, 4000, 7)
(2, 4000, 7)
[1.0322659, 0.25438264, 0.1987372, -0.17395157, -1.3296268]
7.3 Golem Taming: Regularization¶
7.4 Predicting predictive accuracy¶
Overthinking: WAIC calculations¶
Code 7.19¶
# There is no CSV file for cars dataset in author's repo
# hence I have inlined the data. In R this dataset much be bundled in
# and this is why his code snippets do not need the csv file
cars_data = """
"","speed","dist"
"1",4,2
"2",4,10
"3",7,4
"4",7,22
"5",8,16
"6",9,10
"7",10,18
"8",10,26
"9",10,34
"10",11,17
"11",11,28
"12",12,14
"13",12,20
"14",12,24
"15",12,28
"16",13,26
"17",13,34
"18",13,34
"19",13,46
"20",14,26
"21",14,36
"22",14,60
"23",14,80
"24",15,20
"25",15,26
"26",15,54
"27",16,32
"28",16,40
"29",17,32
"30",17,40
"31",17,50
"32",18,42
"33",18,56
"34",18,76
"35",18,84
"36",19,36
"37",19,46
"38",19,68
"39",20,32
"40",20,48
"41",20,52
"42",20,56
"43",20,64
"44",22,66
"45",23,54
"46",24,70
"47",24,92
"48",24,93
"49",24,120
"50",25,85
"""
buffer = StringIO(cars_data)
d = pd.read_csv(buffer, sep=",")
d.head()
| Unnamed: 0 | speed | dist | |
|---|---|---|---|
| 0 | 1 | 4 | 2 |
| 1 | 2 | 4 | 10 |
| 2 | 3 | 7 | 4 |
| 3 | 4 | 7 | 22 |
| 4 | 5 | 8 | 16 |
# Note -
#
# In first edition, the book used Uniform for sigma and in the second
# edition it is using Exponential;
#
# If I use exponential the chains do not converge; the traces are seriously bad.
# In order to make it work, I have spent time trying to find an ideal number of
# samples & burin. The configuration that has the most impact is the initialization
# state. For the sigma if I use the init state of 60 then the chains converge sometimes ..
# I have observed that even after this setting the convergence is not systematic. After running
# it few times I see that it has R_hat of 2 and that skews the results
#
# Edition 1 model (i.e. using Uniform for scale) is very stable
#
#
# I have ran the model in R (using rehinking & rstan) as well and there I am able to
# work with the model definition as it is in Edition 2
USE_EDITION_2_SPEC = True
def cars_model(speed):
def _generator():
alpha = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=100.0, name="alpha"), sample_shape=1)
)
beta = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=10.0, name="beta"), sample_shape=1)
)
if USE_EDITION_2_SPEC:
sigma = yield Root(
tfd.Sample(tfd.Exponential(rate=1.0, name="sigma"), sample_shape=1)
)
else:
sigma = yield Root(
tfd.Sample(
tfd.Uniform(low=0.0, high=30.0, name="sigma"), sample_shape=1
)
)
mu = alpha[..., tf.newaxis] + beta[..., tf.newaxis] * speed
scale = sigma[..., tf.newaxis]
brain_std = yield tfd.Independent(
tfd.Normal(loc=mu, scale=scale), reinterpreted_batch_ndims=1
)
return tfd.JointDistributionCoroutine(_generator, validate_args=False)
jdc_cars = cars_model(tf.cast(d.speed.values, dtype=tf.float32))
if USE_EDITION_2_SPEC:
init_state = [
tf.ones([NUMBER_OF_CHAINS]),
tf.ones([NUMBER_OF_CHAINS]),
60.0
* tf.ones(
[NUMBER_OF_CHAINS]
), # <--- this makes it work (somewhat, not systematic !)
]
bijectors = [
tfb.Identity(),
tfb.Identity(),
tfb.Exp(),
]
else:
init_state = [
tf.ones([NUMBER_OF_CHAINS]),
tf.ones([NUMBER_OF_CHAINS]),
tf.ones([NUMBER_OF_CHAINS]),
]
bijectors = [
tfb.Identity(),
tfb.Identity(),
tfb.Identity(),
]
observed_data = (tf.cast(d.dist.values, dtype=tf.float32),)
# here I am increasing the sampling size
# to see if that helps
posterior_cars, trace_cars = sample_posterior(
jdc_cars,
observed_data=observed_data,
params=["alpha", "beta", "sigma"],
num_samples=5000,
burnin=2000,
init_state=init_state,
bijectors=bijectors,
)
az.summary(trace_cars, hdi_prob=0.89)
| mean | sd | hdi_5.5% | hdi_94.5% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| alpha | -0.617 | 0.913 | -2.360 | 0.609 | 0.558 | 0.448 | 3.0 | 11.0 | 1.96 |
| beta | 2.941 | 0.138 | 2.722 | 3.166 | 0.026 | 0.019 | 28.0 | 169.0 | 1.07 |
| sigma | 14.723 | 1.408 | 12.594 | 16.939 | 0.105 | 0.075 | 192.0 | 229.0 | 1.01 |
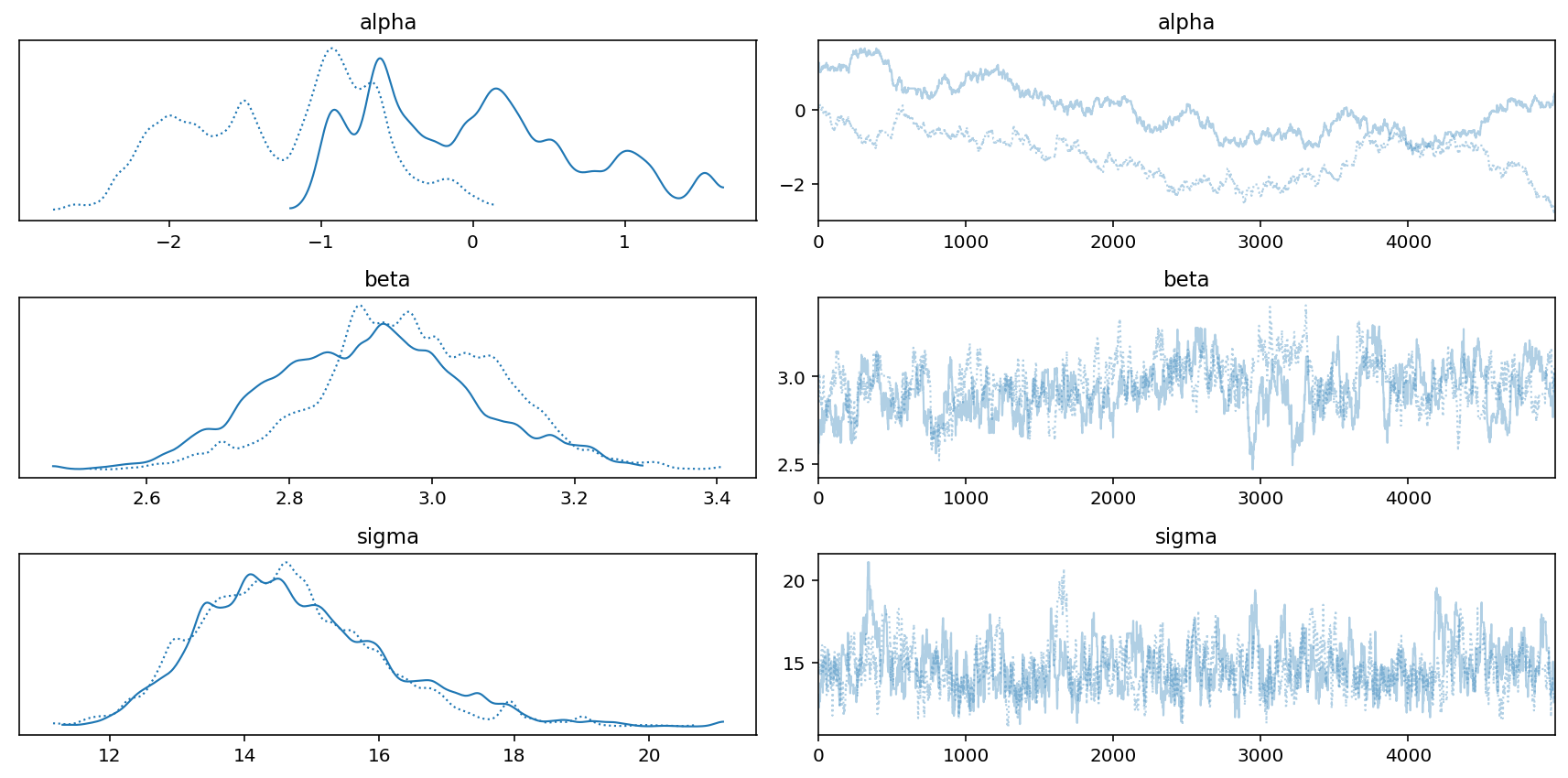
az.plot_trace(trace_cars)
plt.tight_layout();
Code 7.20¶
n_samples = 2000
def logprob_fn(s):
mu = posterior_cars["alpha"][0][s] + posterior_cars["beta"][0][s] * d.speed.values
sigma = posterior_cars["sigma"][0][s]
scale = sigma
return tfd.Normal(
loc=tf.cast(mu, dtype=tf.float32), scale=tf.cast(scale, dtype=tf.float32)
).log_prob(d.dist.values)
logprob = np.array(list(map(logprob_fn, np.arange(n_samples)))).T
logprob.shape
(50, 2000)
Code 7.21¶
n_cases = d.shape[0]
lppd = tf.math.reduce_logsumexp(logprob, 1) - tf.math.log(
tf.cast(n_samples, dtype=tf.float32)
)
Code 7.22¶
pWAIC = np.var(logprob, 1)
Code 7.23¶
-2 * (np.sum(lppd) - np.sum(pWAIC))
426.5716857910156
Code 7.24¶
waic_vec = -2 * (lppd - pWAIC)
np.sqrt(n_cases * np.var(waic_vec))
16.452902449128825
7.4.3 Comparing CV, PSIS, and WAIC¶
7.5 Model comparison¶
Code 7.25¶
Here we need to first redefine models from the previous chapters i.e. m6_6,m6_7,m6_8 and compute the log likelihoods as well and only then we will compute the WAIC
_SEED = 71
# Note - even after providing SeedStream and generated seeds
# it still does not respect it
def simulate():
seed = tfp.util.SeedStream(_SEED, salt="sim_heights")
# number of plants
N = 100
# simulate initial heights
h0 = tfd.Normal(loc=10.0, scale=2.0).sample(N, seed=seed())
# assign treatments and simulate fungus and growth
treatment = tf.repeat([0.0, 1.0], repeats=N // 2)
fungus = tfd.Binomial(total_count=1.0, probs=(0.5 - treatment * 0.4)).sample(
seed=seed()
)
h1 = h0 + tfd.Normal(loc=5.0 - 3.0 * fungus, scale=1.0).sample(seed=seed())
# compose a clean data frame
d = {"h0": h0, "h1": h1, "treatment": treatment, "fungus": fungus}
return d
d_dict = simulate()
az.summary(d_dict, kind="stats", hdi_prob=0.89)
| mean | sd | hdi_5.5% | hdi_94.5% | |
|---|---|---|---|---|
| h0 | 9.894 | 2.143 | 6.421 | 12.93 |
| h1 | 13.609 | 2.696 | 8.782 | 17.34 |
| treatment | 0.500 | 0.503 | 0.000 | 1.00 |
| fungus | 0.350 | 0.479 | 0.000 | 1.00 |
d = pd.DataFrame.from_dict(d_dict)
tdf = dataframe_to_tensors("SimulatedTreatment", d, ["h0", "h1", "treatment", "fungus"])
def model_6_6(h0):
def _generator():
p = yield Root(
tfd.Sample(tfd.LogNormal(loc=0.0, scale=0.25, name="p"), sample_shape=1)
)
sigma = yield Root(
tfd.Sample(tfd.Exponential(rate=1.0, name="sigma"), sample_shape=1)
)
mu = tf.squeeze(h0[tf.newaxis, ...] * p[..., tf.newaxis])
scale = sigma[..., tf.newaxis]
h1 = yield tfd.Independent(
tfd.Normal(loc=mu, scale=scale, name="h1"), reinterpreted_batch_ndims=1
)
return tfd.JointDistributionCoroutine(_generator, validate_args=False)
jdc_6_6 = model_6_6(tdf.h0)
NUM_CHAINS_FOR_6_6 = 2
init_state = [tf.ones([NUM_CHAINS_FOR_6_6]), tf.ones([NUM_CHAINS_FOR_6_6])]
bijectors = [tfb.Exp(), tfb.Exp()]
posterior_6_6, trace_6_6 = sample_posterior(
jdc_6_6,
observed_data=(tdf.h1,),
num_chains=NUM_CHAINS_FOR_6_6,
init_state=init_state,
bijectors=bijectors,
num_samples=2000,
burnin=1000,
params=["p", "sigma"],
)
az.summary(trace_6_6, hdi_prob=0.89)
| mean | sd | hdi_5.5% | hdi_94.5% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| p | 1.356 | 0.019 | 1.327 | 1.387 | 0.001 | 0.000 | 1355.0 | 1548.0 | 1.0 |
| sigma | 1.909 | 0.137 | 1.689 | 2.122 | 0.004 | 0.003 | 1124.0 | 1474.0 | 1.0 |
def model_6_7(h0, treatment, fungus):
def _generator():
a = yield Root(
tfd.Sample(tfd.LogNormal(loc=0.0, scale=0.2, name="a"), sample_shape=1)
)
bt = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=0.5, name="bt"), sample_shape=1)
)
bf = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=0.5, name="bf"), sample_shape=1)
)
sigma = yield Root(
tfd.Sample(tfd.Exponential(rate=1.0, name="sigma"), sample_shape=1)
)
p = (
a[..., tf.newaxis]
+ bt[..., tf.newaxis] * treatment
+ bf[..., tf.newaxis] * fungus
)
mu = h0 * p
scale = sigma[..., tf.newaxis]
h1 = yield tfd.Independent(
tfd.Normal(loc=mu, scale=scale, name="h1"), reinterpreted_batch_ndims=1
)
return tfd.JointDistributionCoroutine(_generator, validate_args=False)
jdc_6_7 = model_6_7(tdf.h0, tdf.treatment, tdf.fungus)
NUM_CHAINS_FOR_6_7 = 2
init_state = [
tf.ones([NUM_CHAINS_FOR_6_7]),
tf.zeros([NUM_CHAINS_FOR_6_7]),
tf.zeros([NUM_CHAINS_FOR_6_7]),
tf.ones([NUM_CHAINS_FOR_6_7]),
]
bijectors = [tfb.Exp(), tfb.Identity(), tfb.Identity(), tfb.Exp()]
posterior_6_7, trace_6_7 = sample_posterior(
jdc_6_7,
observed_data=(tdf.h1,),
num_chains=NUM_CHAINS_FOR_6_7,
init_state=init_state,
bijectors=bijectors,
num_samples=2000,
burnin=1000,
params=["a", "bt", "bf", "sigma"],
)
az.summary(trace_6_7, hdi_prob=0.89)
| mean | sd | hdi_5.5% | hdi_94.5% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| a | 1.456 | 0.029 | 1.411 | 1.505 | 0.001 | 0.001 | 821.0 | 917.0 | 1.0 |
| bt | -0.012 | 0.033 | -0.063 | 0.043 | 0.001 | 0.001 | 1051.0 | 1019.0 | 1.0 |
| bf | -0.278 | 0.035 | -0.334 | -0.222 | 0.001 | 0.001 | 1048.0 | 1180.0 | 1.0 |
| sigma | 1.394 | 0.098 | 1.235 | 1.538 | 0.005 | 0.004 | 362.0 | 795.0 | 1.0 |
def model_6_8(h0, treatment):
def _generator():
a = yield Root(
tfd.Sample(tfd.LogNormal(loc=0.0, scale=0.2, name="a"), sample_shape=1)
)
bt = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=0.5, name="bt"), sample_shape=1)
)
sigma = yield Root(
tfd.Sample(tfd.Exponential(rate=1.0, name="sigma"), sample_shape=1)
)
p = a[..., tf.newaxis] + bt[..., tf.newaxis] * treatment
mu = h0 * p
scale = sigma[..., tf.newaxis]
h1 = yield tfd.Independent(
tfd.Normal(loc=mu, scale=scale, name="h1"), reinterpreted_batch_ndims=1
)
return tfd.JointDistributionCoroutine(_generator, validate_args=False)
jdc_6_8 = model_6_8(tdf.h0, tdf.treatment)
NUM_CHAINS_FOR_6_8 = 2
init_state = [
tf.ones([NUM_CHAINS_FOR_6_8]),
tf.zeros([NUM_CHAINS_FOR_6_8]),
tf.ones([NUM_CHAINS_FOR_6_8]),
]
bijectors = [tfb.Exp(), tfb.Identity(), tfb.Exp()]
posterior_6_8, trace_6_8 = sample_posterior(
jdc_6_8,
observed_data=(tdf.h1,),
num_chains=NUM_CHAINS_FOR_6_8,
init_state=init_state,
bijectors=bijectors,
num_samples=2000,
burnin=1000,
params=["a", "bt", "sigma"],
)
az.summary(trace_6_8, hdi_prob=0.89)
| mean | sd | hdi_5.5% | hdi_94.5% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| a | 1.287 | 0.026 | 1.245 | 1.327 | 0.001 | 0.000 | 1774.0 | 1505.0 | 1.0 |
| bt | 0.133 | 0.035 | 0.079 | 0.191 | 0.001 | 0.000 | 3466.0 | 1339.0 | 1.0 |
| sigma | 1.786 | 0.130 | 1.587 | 1.989 | 0.004 | 0.003 | 990.0 | 1684.0 | 1.0 |
# compute the log likelihoods
def compute_log_likelihood_6_7(jdc, posterior, trace):
sample_a = posterior["a"]
sample_bt = posterior["bt"]
sample_bf = posterior["bf"]
sample_sigma = posterior["sigma"]
ds, samples = jdc.sample_distributions(
value=[sample_a, sample_bt, sample_bf, sample_sigma, None]
)
log_likelihood_total = ds[-1].distribution.log_prob(tdf.h1).numpy()
# we are inserting the log likelihood in the trace
# as well though not required for this exercise
sample_stats = trace.sample_stats
coords = [sample_stats.coords["chain"], sample_stats.coords["draw"], np.arange(100)]
sample_stats["log_likelihood"] = xr.DataArray(
log_likelihood_total,
coords=coords,
dims=["chain", "draw", "log_likelihood_dim_0"],
)
return log_likelihood_total
ll_6_7 = compute_log_likelihood_6_7(jdc_6_7, posterior_6_7, trace_6_7)
# WAIC for model_6_7
WAIC_m6_7 = az.waic(trace_6_7, pointwise=True, scale="deviance")
WAIC_m6_7
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/arviz/stats/stats.py:1460: UserWarning: For one or more samples the posterior variance of the log predictive densities exceeds 0.4. This could be indication of WAIC starting to fail.
See http://arxiv.org/abs/1507.04544 for details
"For one or more samples the posterior variance of the log predictive "
Computed from 4000 by 100 log-likelihood matrix
Estimate SE
deviance_waic 353.67 15.13
p_waic 3.67 -
There has been a warning during the calculation. Please check the results.
Code 7.26¶
# likelihoods for rest of the 6_X models
def compute_log_likelihood_6_6(jdc, posterior, trace):
sample_p = posterior["p"]
sample_sigma = posterior["sigma"]
ds, samples = jdc.sample_distributions(value=[sample_p, sample_sigma, None])
log_likelihood_total = ds[-1].distribution.log_prob(tdf.h1).numpy()
# we are inserting the log likelihood in the trace
# as well though not required for this exercise
sample_stats = trace.sample_stats
coords = [sample_stats.coords["chain"], sample_stats.coords["draw"], np.arange(100)]
sample_stats["log_likelihood"] = xr.DataArray(
log_likelihood_total,
coords=coords,
dims=["chain", "draw", "log_likelihood_dim_0"],
)
return log_likelihood_total
ll_6_6 = compute_log_likelihood_6_6(jdc_6_6, posterior_6_6, trace_6_6)
def compute_log_likelihood_6_8(jdc, posterior, trace):
sample_a = posterior["a"]
sample_bt = posterior["bt"]
sample_sigma = posterior["sigma"]
ds, samples = jdc.sample_distributions(
value=[sample_a, sample_bt, sample_sigma, None]
)
log_likelihood_total = ds[-1].distribution.log_prob(tdf.h1).numpy()
# we are inserting the log likelihood in the trace
# as well though not required for this exercise
sample_stats = trace.sample_stats
coords = [sample_stats.coords["chain"], sample_stats.coords["draw"], np.arange(100)]
sample_stats["log_likelihood"] = xr.DataArray(
log_likelihood_total,
coords=coords,
dims=["chain", "draw", "log_likelihood_dim_0"],
)
return log_likelihood_total
ll_6_8 = compute_log_likelihood_6_8(jdc_6_8, posterior_6_8, trace_6_8)
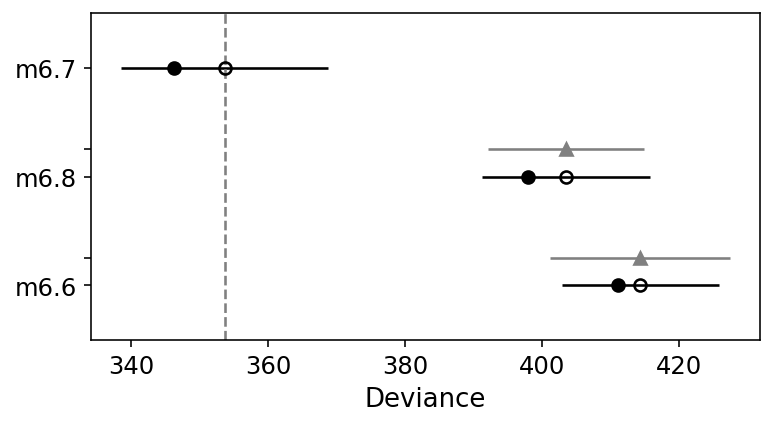
compare_df = az.compare(
{"m6.6": trace_6_6, "m6.7": trace_6_7, "m6.8": trace_6_8},
ic="waic",
scale="deviance",
)
compare_df
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/arviz/stats/stats.py:1460: UserWarning: For one or more samples the posterior variance of the log predictive densities exceeds 0.4. This could be indication of WAIC starting to fail.
See http://arxiv.org/abs/1507.04544 for details
"For one or more samples the posterior variance of the log predictive "
| rank | waic | p_waic | d_waic | weight | se | dse | warning | waic_scale | |
|---|---|---|---|---|---|---|---|---|---|
| m6.7 | 0 | 353.665405 | 3.669678 | 0.000000 | 9.822980e-01 | 15.126145 | 0.000000 | True | deviance |
| m6.8 | 1 | 403.530006 | 2.766369 | 49.864601 | 2.542031e-13 | 12.231961 | 11.439999 | False | deviance |
| m6.6 | 2 | 414.378413 | 1.639428 | 60.713008 | 1.770199e-02 | 11.482189 | 13.109657 | False | deviance |
Code 7.27¶
WAIC_m6_7 = az.waic(trace_6_7, pointwise=True, scale="deviance")
WAIC_m6_8 = az.waic(trace_6_8, pointwise=True, scale="deviance")
# pointwise values are stored in the waic_i attribute.
diff_m_6_7_m_6_8 = WAIC_m6_7.waic_i - WAIC_m6_8.waic_i
n = len(diff_m_6_7_m_6_8)
np.sqrt(n * np.var(diff_m_6_7_m_6_8)).values
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/arviz/stats/stats.py:1460: UserWarning: For one or more samples the posterior variance of the log predictive densities exceeds 0.4. This could be indication of WAIC starting to fail.
See http://arxiv.org/abs/1507.04544 for details
"For one or more samples the posterior variance of the log predictive "
array(11.43999922)
Code 7.28¶
40.0 + np.array([-1, 1]) * 10.4 * 2.6
array([12.96, 67.04])
Code 7.29¶
az.plot_compare(compare_df);
Code 7.30¶
WAIC_m6_6 = az.waic(trace_6_6, pointwise=True, scale="deviance")
diff_m6_6_m6_8 = WAIC_m6_6.waic_i - WAIC_m6_8.waic_i
n = WAIC_m6_6.n_data_points
np.sqrt(n * np.var(diff_m6_6_m6_8)).values
array(7.26519925)
Code 7.31¶
dSE = lambda waic1, waic2: np.sqrt(
n * np.var(waic1.waic_i.values - waic2.waic_i.values)
)
data = {"m6.6": WAIC_m6_6, "m6.7": WAIC_m6_7, "m6.8": WAIC_m6_8}
pd.DataFrame(
{
row: {col: dSE(row_val, col_val) for col, col_val in data.items()}
for row, row_val in data.items()
}
)
| m6.6 | m6.7 | m6.8 | |
|---|---|---|---|
| m6.6 | 0.000000 | 13.109657 | 7.265199 |
| m6.7 | 13.109657 | 0.000000 | 11.439999 |
| m6.8 | 7.265199 | 11.439999 | 0.000000 |
7.5.2 Outliers and other illusions¶
Code 7.32¶
d = RethinkingDataset.WaffleDivorce.get_dataset()
d["A"] = d.MedianAgeMarriage.pipe(lambda x: (x - x.mean()) / x.std())
d["D"] = d.Divorce.pipe(lambda x: (x - x.mean()) / x.std())
d["M"] = d.Marriage.pipe(lambda x: (x - x.mean()) / x.std())
tdf = dataframe_to_tensors("Waffle", d, ["A", "D", "M"])
def model_5_1(A):
def _generator():
alpha = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=0.2, name="alpha"), sample_shape=1)
)
betaA = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=0.5, name="betaA"), sample_shape=1)
)
sigma = yield Root(
tfd.Sample(tfd.Exponential(rate=1.0, name="sigma"), sample_shape=1)
)
mu = alpha[..., tf.newaxis] + betaA[..., tf.newaxis] * A
scale = sigma[..., tf.newaxis]
D = yield tfd.Independent(
tfd.Normal(loc=mu, scale=scale), reinterpreted_batch_ndims=1
)
return tfd.JointDistributionCoroutine(_generator, validate_args=False)
def model_5_2(M):
def _generator():
alpha = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=0.2, name="alpha"), sample_shape=1)
)
betaM = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=0.5, name="betaM"), sample_shape=1)
)
sigma = yield Root(
tfd.Sample(tfd.Exponential(rate=1.0, name="sigma"), sample_shape=1)
)
mu = alpha[..., tf.newaxis] + betaM[..., tf.newaxis] * M
scale = sigma[..., tf.newaxis]
D = yield tfd.Independent(
tfd.Normal(loc=mu, scale=scale), reinterpreted_batch_ndims=1
)
return tfd.JointDistributionCoroutine(_generator, validate_args=False)
def model_5_3(A, M):
def _generator():
alpha = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=0.2, name="alpha"), sample_shape=1)
)
betaA = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=0.5, name="betaA"), sample_shape=1)
)
betaM = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=0.5, name="betaM"), sample_shape=1)
)
sigma = yield Root(
tfd.Sample(tfd.Exponential(rate=1.0, name="sigma"), sample_shape=1)
)
mu = (
alpha[..., tf.newaxis]
+ betaA[..., tf.newaxis] * A
+ betaM[..., tf.newaxis] * M
)
scale = sigma[..., tf.newaxis]
D = yield tfd.Independent(
tfd.Normal(loc=mu, scale=scale), reinterpreted_batch_ndims=1
)
return tfd.JointDistributionCoroutine(_generator, validate_args=False)
jdc_5_1 = model_5_1(tdf.A)
jdc_5_2 = model_5_2(tdf.M)
jdc_5_3 = model_5_3(tdf.A, tdf.M)
def compute_posterior_5_1_and_2(jdc):
init_state = [
tf.zeros([NUMBER_OF_CHAINS]),
tf.zeros([NUMBER_OF_CHAINS]),
tf.ones([NUMBER_OF_CHAINS]),
]
bijectors = [
tfb.Identity(),
tfb.Identity(),
tfb.Exp(),
]
observed_data = (tdf.D,)
# here I am increasing the sampling size
# to see if that helps
posterior, trace = sample_posterior(
jdc,
observed_data=observed_data,
params=["alpha", "beta", "sigma"],
num_samples=1000,
burnin=500,
init_state=init_state,
bijectors=bijectors,
)
return posterior, trace
def compute_posterior_5_3():
init_state = [
tf.zeros([NUMBER_OF_CHAINS]),
tf.zeros([NUMBER_OF_CHAINS]),
tf.zeros([NUMBER_OF_CHAINS]),
tf.ones([NUMBER_OF_CHAINS]),
]
bijectors = [
tfb.Identity(),
tfb.Identity(),
tfb.Identity(),
tfb.Exp(),
]
observed_data = (tdf.D,)
# here I am increasing the sampling size
# to see if that helps
posterior, trace = sample_posterior(
jdc_5_3,
observed_data=observed_data,
params=["alpha", "betaA", "betaM", "sigma"],
num_samples=1000,
burnin=500,
init_state=init_state,
bijectors=bijectors,
)
return posterior, trace
posterior_5_1, trace_5_1 = compute_posterior_5_1_and_2(jdc_5_1)
posterior_5_2, trace_5_2 = compute_posterior_5_1_and_2(jdc_5_2)
posterior_5_3, trace_5_3 = compute_posterior_5_3()
Code 7.33¶
def compute_log_likelihood_m5_1_2(jdc, posterior, trace):
sample_alpha = posterior["alpha"]
sample_beta = posterior["beta"]
sample_sigma = posterior["sigma"]
ds, samples = jdc.sample_distributions(
value=[sample_alpha, sample_beta, sample_sigma, None]
)
log_likelihood_total = ds[-1].distribution.log_prob(tdf.D).numpy()
# we are inserting the log likelihood in the trace
# as well though not required for this exercise
sample_stats = trace.sample_stats
coords = [sample_stats.coords["chain"], sample_stats.coords["draw"], np.arange(50)]
sample_stats["log_likelihood"] = xr.DataArray(
log_likelihood_total,
coords=coords,
dims=["chain", "draw", "log_likelihood_dim_0"],
)
return log_likelihood_total
def compute_log_likelihood_m5_3(jdc, posterior, trace):
sample_alpha = posterior["alpha"]
sample_betaA = posterior["betaA"]
sample_betaM = posterior["betaM"]
sample_sigma = posterior["sigma"]
ds, samples = jdc.sample_distributions(
value=[sample_alpha, sample_betaA, sample_betaM, sample_sigma, None]
)
log_likelihood_total = ds[-1].distribution.log_prob(tdf.D).numpy()
# we are inserting the log likelihood in the trace
# as well though not required for this exercise
sample_stats = trace.sample_stats
coords = [sample_stats.coords["chain"], sample_stats.coords["draw"], np.arange(50)]
sample_stats["log_likelihood"] = xr.DataArray(
log_likelihood_total,
coords=coords,
dims=["chain", "draw", "log_likelihood_dim_0"],
)
return log_likelihood_total
ll_5_1 = compute_log_likelihood_m5_1_2(jdc_5_1, posterior_5_1, trace_5_1)
ll_5_2 = compute_log_likelihood_m5_1_2(jdc_5_2, posterior_5_2, trace_5_2)
ll_5_3 = compute_log_likelihood_m5_3(jdc_5_3, posterior_5_3, trace_5_3)
az.compare({"m5.1": trace_5_1, "m5.2": trace_5_2, "m5.3": trace_5_3}, scale="deviance")
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/arviz/stats/stats.py:695: UserWarning: Estimated shape parameter of Pareto distribution is greater than 0.7 for one or more samples. You should consider using a more robust model, this is because importance sampling is less likely to work well if the marginal posterior and LOO posterior are very different. This is more likely to happen with a non-robust model and highly influential observations.
"Estimated shape parameter of Pareto distribution is greater than 0.7 for "
| rank | loo | p_loo | d_loo | weight | se | dse | warning | loo_scale | |
|---|---|---|---|---|---|---|---|---|---|
| m5.1 | 0 | 125.067179 | 3.296447 | 0.000000 | 9.023990e-01 | 12.579059 | 0.000000 | False | deviance |
| m5.3 | 1 | 128.734815 | 5.351810 | 3.667636 | 2.021028e-15 | 13.718278 | 1.691268 | True | deviance |
| m5.2 | 2 | 139.479486 | 3.065360 | 14.412308 | 9.760100e-02 | 9.957815 | 8.902040 | False | deviance |
Code 7.34¶
PSIS_m5_3 = az.loo(trace_5_3, pointwise=True, scale="deviance")
WAIC_m5_3 = az.waic(trace_5_3, pointwise=True, scale="deviance")
penalty = (
trace_5_3.sample_stats.log_likelihood.stack(sample=("chain", "draw"))
.var(dim="sample")
.values
)
plt.plot(PSIS_m5_3.pareto_k.values, penalty, "o", mfc="none")
plt.gca().set(xlabel="PSIS Pareto k", ylabel="WAIC penalty");
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/arviz/stats/stats.py:695: UserWarning: Estimated shape parameter of Pareto distribution is greater than 0.7 for one or more samples. You should consider using a more robust model, this is because importance sampling is less likely to work well if the marginal posterior and LOO posterior are very different. This is more likely to happen with a non-robust model and highly influential observations.
"Estimated shape parameter of Pareto distribution is greater than 0.7 for "
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/arviz/stats/stats.py:1460: UserWarning: For one or more samples the posterior variance of the log predictive densities exceeds 0.4. This could be indication of WAIC starting to fail.
See http://arxiv.org/abs/1507.04544 for details
"For one or more samples the posterior variance of the log predictive "

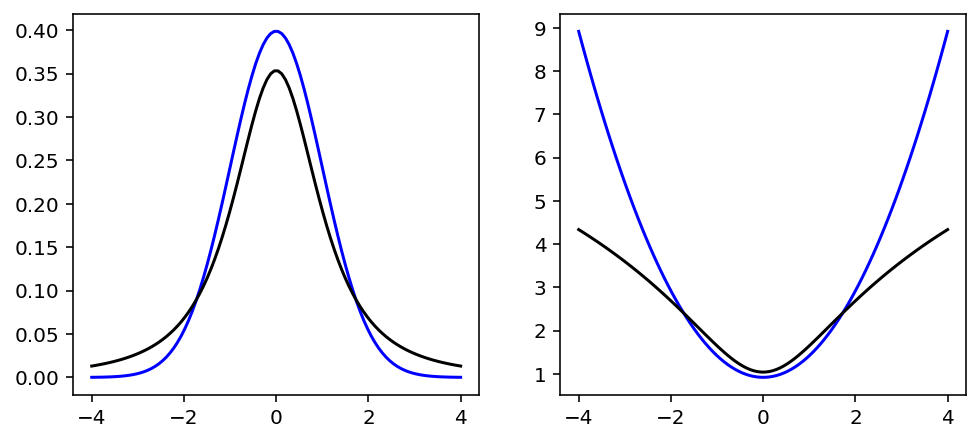
# reproduce figure 7.11
v = tf.cast(tf.linspace(-4, 4, 100), dtype=tf.float32)
g = tfd.Normal(loc=0.0, scale=1.0)
t = tfd.StudentT(df=2, loc=0.0, scale=1.0)
fig, (ax, lax) = plt.subplots(1, 2, figsize=[8, 3.5])
ax.plot(v, g.prob(v), color="b")
ax.plot(v, t.prob(v), color="k")
lax.plot(v, -g.log_prob(v), color="b")
lax.plot(v, -t.log_prob(v), color="k");
Code 7.35¶
def model_5_3t(A, M):
def _generator():
alpha = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=0.2, name="alpha"), sample_shape=1)
)
betaA = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=0.5, name="betaA"), sample_shape=1)
)
betaM = yield Root(
tfd.Sample(tfd.Normal(loc=0.0, scale=0.5, name="betaM"), sample_shape=1)
)
sigma = yield Root(
tfd.Sample(tfd.Exponential(rate=1.0, name="sigma"), sample_shape=1)
)
mu = (
alpha[..., tf.newaxis]
+ betaA[..., tf.newaxis] * A
+ betaM[..., tf.newaxis] * M
)
scale = sigma[..., tf.newaxis]
D = yield tfd.Independent(
tfd.StudentT(df=2.0, loc=mu, scale=scale), reinterpreted_batch_ndims=1
)
return tfd.JointDistributionCoroutine(_generator, validate_args=False)
jdc_5_3t = model_5_3t(tdf.A, tdf.M)
def compute_posterior_5_3t():
init_state = [
tf.zeros([NUMBER_OF_CHAINS]),
tf.zeros([NUMBER_OF_CHAINS]),
tf.zeros([NUMBER_OF_CHAINS]),
tf.ones([NUMBER_OF_CHAINS]),
]
bijectors = [
tfb.Identity(),
tfb.Identity(),
tfb.Identity(),
tfb.Exp(),
]
observed_data = (tdf.D,)
# here I am increasing the sampling size
# to see if that helps
posterior, trace = sample_posterior(
jdc_5_3t,
observed_data=observed_data,
params=["alpha", "betaA", "betaM", "sigma"],
num_samples=1000,
burnin=500,
init_state=init_state,
bijectors=bijectors,
)
return posterior, trace
posterior_5_3t, trace_5_3t = compute_posterior_5_3t()
def compute_log_likelihood_m5_3t(jdc, posterior, trace):
sample_alpha = posterior["alpha"]
sample_betaA = posterior["betaA"]
sample_betaM = posterior["betaM"]
sample_sigma = posterior["sigma"]
ds, samples = jdc.sample_distributions(
value=[sample_alpha, sample_betaA, sample_betaM, sample_sigma, None]
)
log_likelihood_total = ds[-1].distribution.log_prob(tdf.D).numpy()
# we are inserting the log likelihood in the trace
# as well though not required for this exercise
sample_stats = trace.sample_stats
coords = [sample_stats.coords["chain"], sample_stats.coords["draw"], np.arange(50)]
sample_stats["log_likelihood"] = xr.DataArray(
log_likelihood_total,
coords=coords,
dims=["chain", "draw", "log_likelihood_dim_0"],
)
return log_likelihood_total
WARNING:tensorflow:@custom_gradient grad_fn has 'variables' in signature, but no ResourceVariables were used on the forward pass.
WARNING:tensorflow:@custom_gradient grad_fn has 'variables' in signature, but no ResourceVariables were used on the forward pass.
WARNING:tensorflow:@custom_gradient grad_fn has 'variables' in signature, but no ResourceVariables were used on the forward pass.
WARNING:tensorflow:@custom_gradient grad_fn has 'variables' in signature, but no ResourceVariables were used on the forward pass.
WARNING:tensorflow:@custom_gradient grad_fn has 'variables' in signature, but no ResourceVariables were used on the forward pass.
ll = compute_log_likelihood_m5_3t(jdc_5_3t, posterior_5_3t, trace_5_3t)
az.loo(trace_5_3, pointwise=True, scale="deviance")
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/arviz/stats/stats.py:695: UserWarning: Estimated shape parameter of Pareto distribution is greater than 0.7 for one or more samples. You should consider using a more robust model, this is because importance sampling is less likely to work well if the marginal posterior and LOO posterior are very different. This is more likely to happen with a non-robust model and highly influential observations.
"Estimated shape parameter of Pareto distribution is greater than 0.7 for "
Computed from 2000 by 50 log-likelihood matrix
Estimate SE
deviance_loo 128.73 13.72
p_loo 5.35 -
There has been a warning during the calculation. Please check the results.
------
Pareto k diagnostic values:
Count Pct.
(-Inf, 0.5] (good) 48 96.0%
(0.5, 0.7] (ok) 1 2.0%
(0.7, 1] (bad) 0 0.0%
(1, Inf) (very bad) 1 2.0%
az.compare({"m5.3": trace_5_3, "m5.3t": trace_5_3t}, scale="deviance")
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/arviz/stats/stats.py:695: UserWarning: Estimated shape parameter of Pareto distribution is greater than 0.7 for one or more samples. You should consider using a more robust model, this is because importance sampling is less likely to work well if the marginal posterior and LOO posterior are very different. This is more likely to happen with a non-robust model and highly influential observations.
"Estimated shape parameter of Pareto distribution is greater than 0.7 for "
| rank | loo | p_loo | d_loo | weight | se | dse | warning | loo_scale | |
|---|---|---|---|---|---|---|---|---|---|
| m5.3 | 0 | 128.734815 | 5.351810 | 0.000000 | 0.814358 | 13.718278 | 0.000000 | True | deviance |
| m5.3t | 1 | 134.238175 | 6.863612 | 5.503361 | 0.185642 | 11.462630 | 6.719112 | False | deviance |
az.summary(trace_5_3, hdi_prob=0.89)
| mean | sd | hdi_5.5% | hdi_94.5% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| alpha | 0.001 | 0.099 | -0.152 | 0.158 | 0.004 | 0.003 | 650.0 | 1010.0 | 1.00 |
| betaA | -0.612 | 0.162 | -0.884 | -0.366 | 0.006 | 0.004 | 846.0 | 385.0 | 1.01 |
| betaM | -0.064 | 0.156 | -0.338 | 0.162 | 0.005 | 0.006 | 927.0 | 348.0 | 1.00 |
| sigma | 0.825 | 0.082 | 0.697 | 0.949 | 0.002 | 0.002 | 1211.0 | 919.0 | 1.00 |
az.summary(trace_5_3t, hdi_prob=0.89)
| mean | sd | hdi_5.5% | hdi_94.5% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| alpha | 0.036 | 0.110 | -0.128 | 0.212 | 0.021 | 0.015 | 31.0 | 170.0 | 1.08 |
| betaA | -0.698 | 0.160 | -0.961 | -0.462 | 0.006 | 0.005 | 776.0 | 376.0 | 1.00 |
| betaM | 0.045 | 0.200 | -0.260 | 0.349 | 0.005 | 0.007 | 1233.0 | 298.0 | 1.01 |
| sigma | 0.581 | 0.103 | 0.426 | 0.739 | 0.003 | 0.002 | 1471.0 | 41.0 | 1.07 |